AWS Storage - Reinvent 2024 Announcements
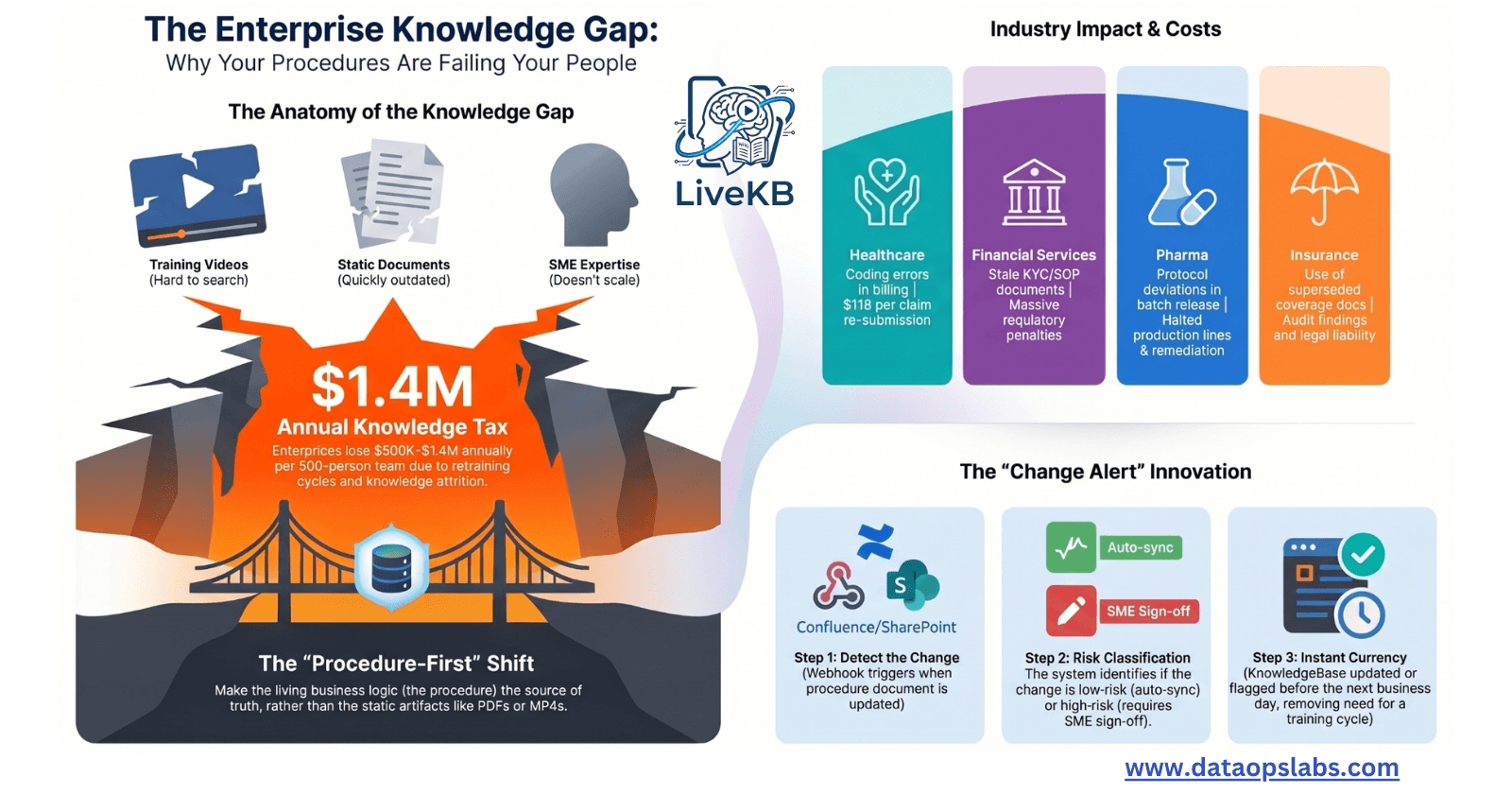
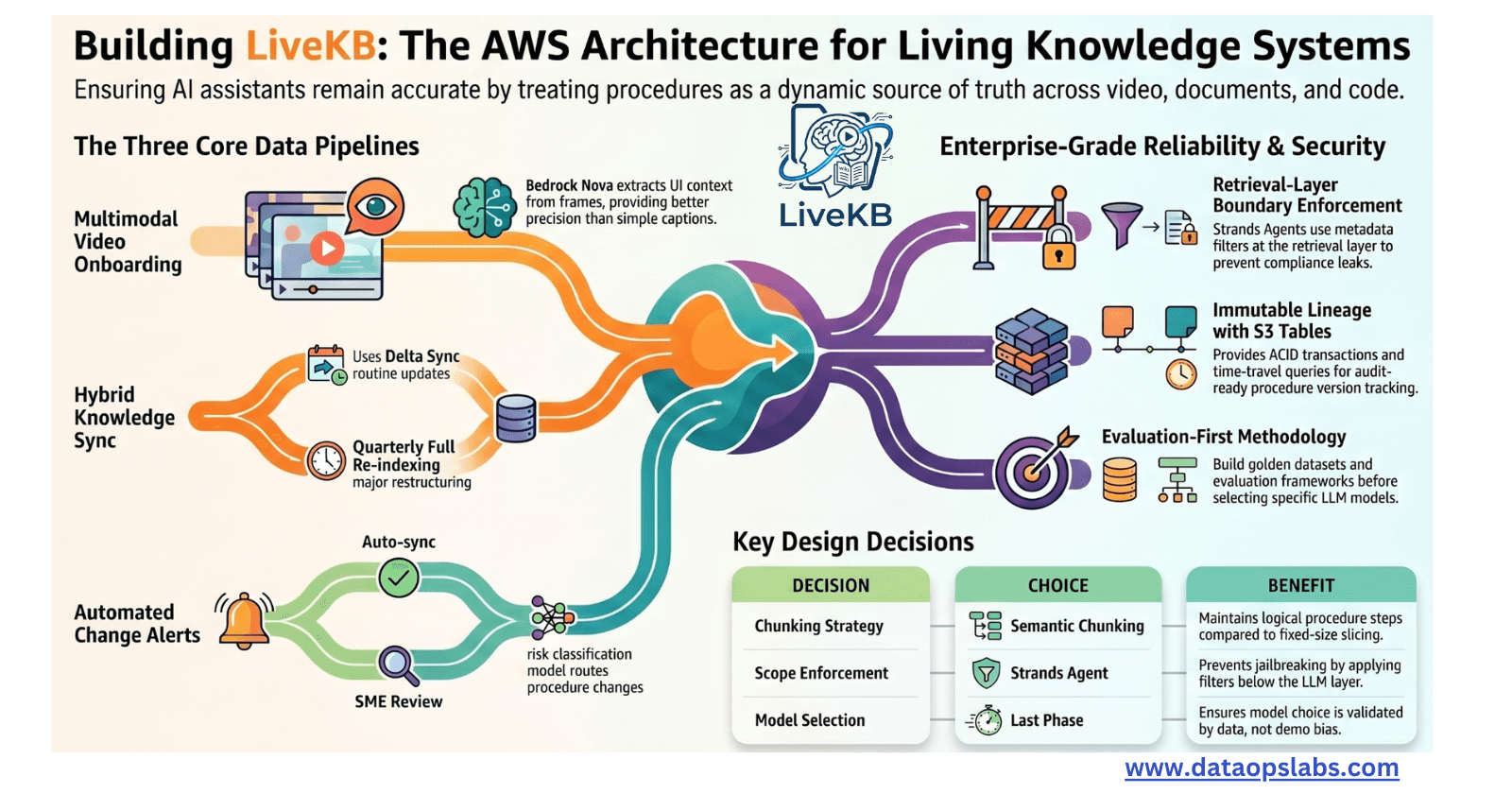
At AWS re:Invent 2024, Amazon Web Services (AWS) announced the integration of Apache Iceberg with Amazon S3, introducing S3 Tables and enhanced S3 Metadata capabilities. Apache Iceberg is an open table format designed for high-performance analytics on large datasets, addressing challenges such as data mutability and schema evolution. Previously, organizations like Netflix implemented custom solutions leveraging Iceberg to manage vast data lakes efficiently.
S3 Tables - Apache Iceberg
Simplifying Data Workloads with AWS's New Integration
The new AWS integration streamlines data management by offering:
Seamless Data Ingestion: Amazon Data Firehose now supports continuous replication of database changes into Apache Iceberg tables on S3, simplifying real-time data streaming without complex pipelines.
Enhanced Query Performance: Optimizing Iceberg tables improves data storage efficiency and query performance, enabling faster analytics.
Unified Data Catalog: AWS Glue Data Catalog integration allows for consistent metadata management across various analytics services, facilitating easier data discovery and governance.
S3 Metadata. - S3 Data
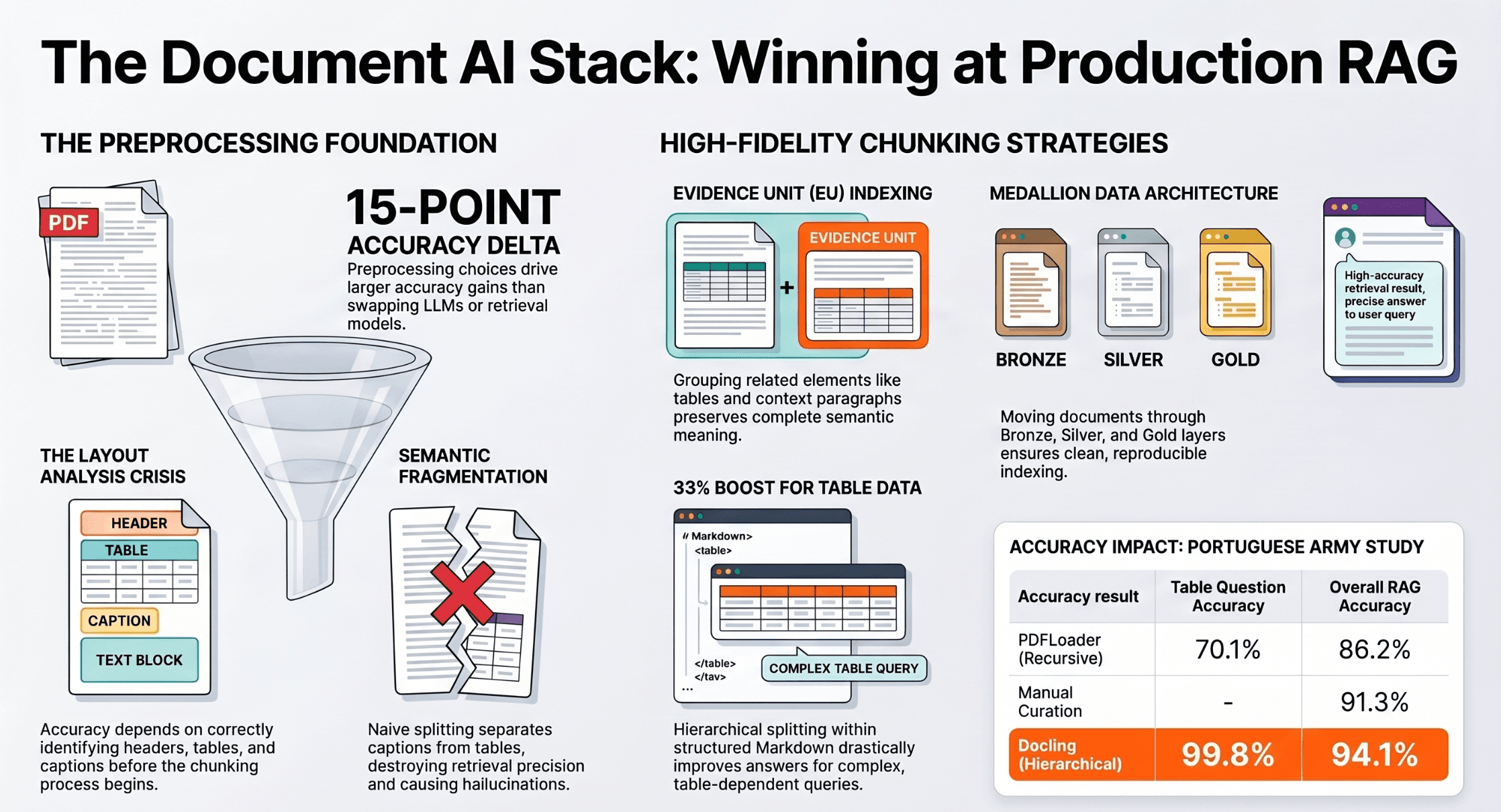
Leveraging S3 Metadata and S3 Data for Generative AI Video Analytics
For Generative AI video analytics, the enhanced S3 Metadata capabilities enable:
Efficient Data Retrieval: Detailed metadata tagging allows AI models to quickly locate and process relevant video segments, reducing latency.
Improved Data Management: Organizing video data with rich metadata supports better training datasets for AI models, enhancing accuracy.
By integrating Apache Iceberg with S3, AWS simplifies data workflows, enabling organizations to focus on deriving insights rather than managing infrastructure.