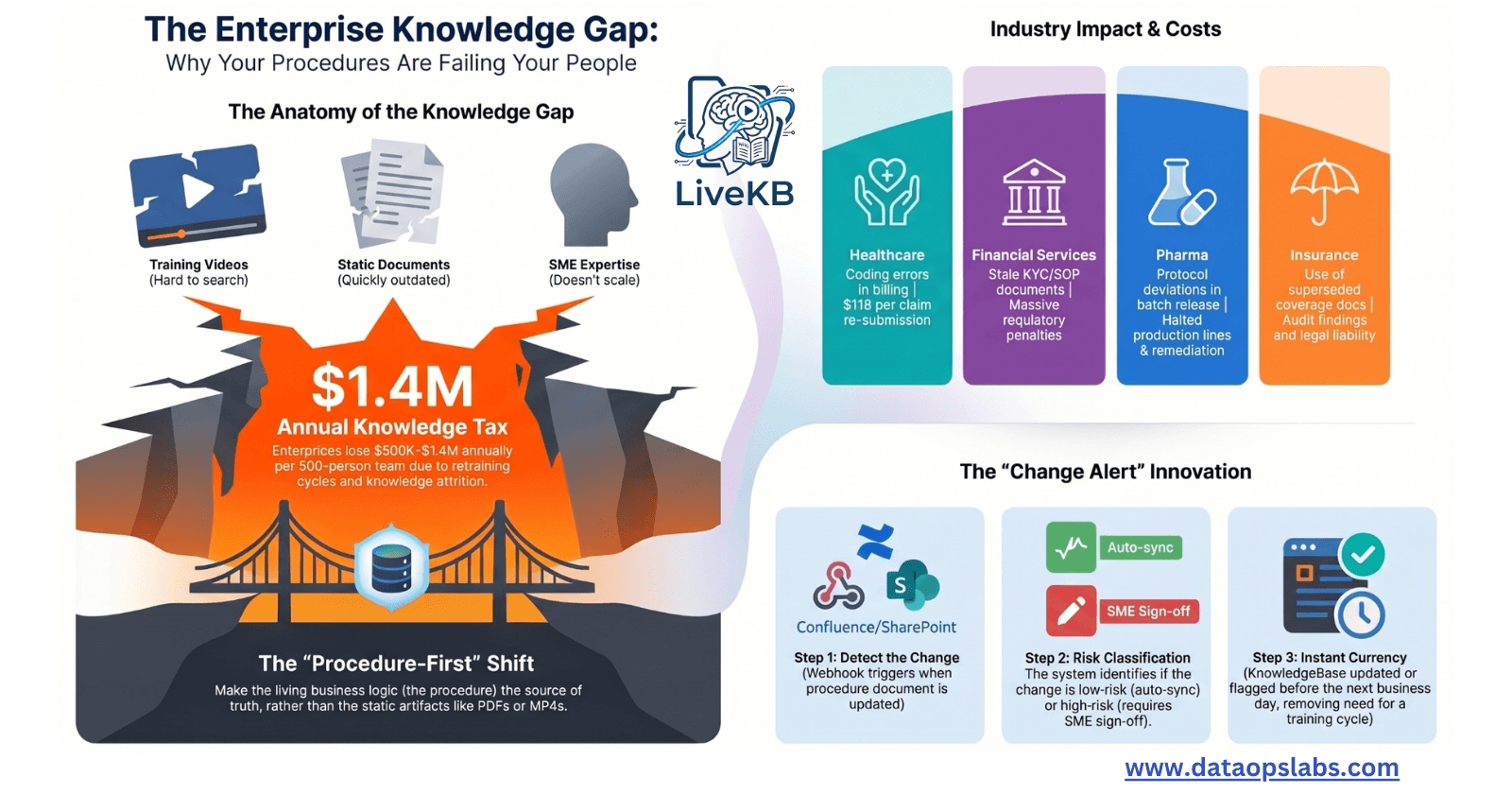
Agent Harness and SOP: Engineering Deterministic Responses in AI Systems
A comprehensive technical guide to building reliable, auditable AI agent systems at enterprise scale

Introduction: The Determinism Paradox
The AI industry faces a paradox that determines success or failure in production deployments:
The Problem: Large Language Models (LLMs) generate remarkably intelligent responses but with problematic inconsistency. Running the same query through Claude or GPT-4 produces subtly different answers each time, making probabilistic reasoning perfect for creative tasks but toxic for regulated operations.
The Enterprise Reality:
A financial institution cannot accept variable outcomes for fraud detection
A healthcare system cannot tolerate inconsistent eligibility verification
A legal firm cannot explain variable interpretations of contract terms to regulators
Yet enterprises desperately need AI's reasoning capability—the adaptability to handle edge cases, the pattern recognition to surface insights, the natural language fluency to communicate with humans.
The Solution: A hybrid architecture combining strict procedural control with intelligent flexibility—what the industry now calls "determin-ish-tic" behavior. This emerges from two converging architectural patterns:
Agent Harness: The operational infrastructure surrounding LLMs
Standard Operating Procedures (SOPs): Structured workflow specifications
This comprehensive guide explores both components and demonstrates how leading organizations use them to deploy AI agents in production environments where traditional rules-based systems failed and pure LLM approaches prove too unpredictable.
Understanding Agent Harness Architecture
An agent harness is the complete architectural system wrapping an LLM, transforming a language model into a capable, production-ready autonomous system. While the model provides reasoning and language generation, the harness manages the operational infrastructure: tool execution, context management, memory persistence, workflow orchestration, and safety controls.

Figure 1: Agent Harness Architecture - Core components surrounding the LLM including tool integration, context management, orchestration, and execution layers
Core Architectural Components
1. Tool Integration Layer: Bridging Intelligence and Action
The tool integration layer solves a fundamental problem: LLMs produce text, but the world requires actions. This layer watches for special tool-call commands within model outputs and executes corresponding tools.
How It Works:
Model Output: "I need to check the customer's account balance.
<tool_call>get_account_balance(customer_id=12345)</tool_call>"
Harness Action:
1. Detect tool call instruction
2. Parse tool name and arguments
3. Execute in isolated sandbox
4. Capture result with error handling
5. Inject result back into context
Automated Reasoning Component:
The harness employs three-level reasoning about tool reliability:
def intelligent_tool_execution(tool_call, context):
# Level 1: Parameter validation
if not validate_parameters(tool_call.arguments):
return {"status": "error", "reason": "invalid_parameters",
"suggestion": "agent should revise parameters"}
# Level 2: Precondition checking
if not check_preconditions(tool_call.name, context):
return {"status": "blocked", "reason": "precondition_not_met",
"suggestion": "agent should execute prerequisite tool first"}
# Level 3: Execution with fallback
try:
result = execute_tool(tool_call)
return {"status": "success", "data": result}
except ToolError as e:
# Provide diagnostic information for agent reasoning
return {"status": "error", "error_type": e.type,
"error_details": e.message,
"possible_causes": diagnose_error(e),
"recovery_suggestions": suggest_recovery(e)}
Why This Matters:
Traditional hardcoded automation tools fail when:
Conditions change (new APIs, modified business rules)
Edge cases arise (unusual customer scenarios)
Integration partners update (API breaking changes)
Agent harnesses handle these through intelligent tool failure recovery: when a tool fails, the model sees the specific error, reasons about the cause, and selects an alternative approach. A simple example:
Tool Call:
check_balance(account=checking_account)Error:
"Account closed on 2025-01-15"Agent Reasoning: "The checking account is closed. I should check if the customer has a savings account instead."
Alternative Action:
get_all_accounts(customer_id=12345)→check_balance(account=first_open_account)
This adaptive behavior—impossible in traditional automation—emerges from the combination of tool transparency (clear error messages) and model reasoning.
2. Context Management and Memory Architecture: Managing the Token Economy
Modern LLMs support 128K-200K token context windows, yet this seemingly abundant capacity becomes a critical constraint in long-running agent operations. A typical agent conversation quickly consumes context:
Initial system prompt: 2K tokens
Previous conversation history: 5-10K tokens
Current query: 0.5K tokens
Retrieved documents: 50K tokens
Tool results: 30K tokens
Total: 87.5K tokens — 44% of available context consumed before reasoning even begins
Hierarchical Memory Solution:

Production harnesses implement a three-tier memory architecture:
Tier 1: Short-Term Memory (In-Context)
Recent conversational turns stored verbatim
Fast access, immediate availability
Typical capacity: Last 10-20 user messages
Use case: Maintaining conversation coherence, recent context
Tier 2: File System Context Engineering A revolutionary abstraction treating the file system as an explicit context management layer. Instead of consuming context with large tool results:
# Anti-pattern: Context bloat
search_results = call_search_api(query) # Returns 50K tokens
messages.append({"role": "assistant", "content": search_results})
# Result: 50K tokens consumed for one search
# Recommended: File system abstraction
search_results = call_search_api(query)
write_file("/workspace/search_results.txt", search_results)
messages.append({
"role": "assistant",
"content": "Search completed. Results saved to search_results.txt. "
"Key findings: 3 relevant papers on agent architectures, "
"2 industry case studies, 1 benchmark dataset."
})
# Result: 500 tokens to describe results, agent selectively retrieves specific sections
Automated Reasoning in File Management:
Agents reason about when to offload information:
def adaptive_context_management(token_usage, total_tokens, context_limit):
offload_threshold = 0.6 * context_limit
if token_usage > offload_threshold:
# Automated reasoning: What can be safely offloaded?
candidates = [
("search_results.txt", priority=1), # Large, selectively needed
("previous_analysis.txt", priority=2), # Might need later
("conversation_history.txt", priority=3), # Core context, don't touch
]
# Agent decides what to move
for file, priority in candidates:
if token_usage < offload_threshold * 0.8:
break
moved = move_to_file_system(messages, file)
token_usage -= moved
return messages
Tier 3: Long-Term Memory (Knowledge Bases)
Vector databases for semantic search
Traditional databases for structured data
Knowledge graphs for relationship mapping
Access pattern: Retrieve relevant information as needed
The file system layer proves revolutionary because agents trained on Unix-like systems naturally understand file traversal:
# Agent autonomously decides to use grep for selective retrieval
grep "deterministic" search_results.txt # Extract specific lines
find /workspace -name "*.json" -type f # Discover available data
head -20 analysis_log.txt # Sample recent results
This enables effectively unlimited memory while maintaining fine-grained retrieval control.
3. Orchestration and Planning Layer: Controlling Workflow
Orchestration determines execution flow: which actions occur, in what sequence, and under what conditions. Sophisticated harnesses support multiple patterns:
Pattern A: Deterministic Chains
Action 1 → Action 2 → Action 3 → Result
Used for well-defined workflows with no decision points.
Pattern B: Single-Agent Autonomy
Agent chooses tools dynamically based on task requirements
Maximum flexibility; requires robust safety constraints.
Pattern C: Hierarchical Supervision
Supervisor Agent → Routes to → Specialist Agents
Clear separation of concerns; easier to debug and monitor.
Pattern D: Multi-Agent Swarms
Decentralized coordination with peer-to-peer communication
Emergent behavior; for complex uncertain environments.
Automated Reasoning in Orchestration:
Modern harnesses include meta-reasoning about orchestration strategy:
class AdaptiveOrchestrator:
def select_orchestration_pattern(self, task, available_agents):
"""Automatically choose best orchestration approach."""
# Analyze task characteristics
task_complexity = analyze_complexity(task)
required_specialties = extract_required_skills(task)
# Reasoning: Which pattern fits?
if task_complexity < 0.3:
# Simple task - deterministic chain is efficient
return DeterministicChain()
elif len(required_specialties) > 2:
# Multiple domains needed - supervisor pattern
supervisor = self.create_supervisor(required_specialties)
specialists = self.assign_specialists(required_specialties, available_agents)
return HierarchicalSupervision(supervisor, specialists)
else:
# Single domain, moderate complexity - autonomy
return SingleAgentAutonomy(available_agents[0])
4. Execution and Observation Loop: The Core Operating Cycle
All agent systems follow a consistent execution pattern:

Figure 2: Agent Execution Loop - The iterative cycle of reasoning, tool selection, execution, and observation that powers agentic behavior
Iteration 1:
Input: "What's our customer churn rate this quarter?"
→ Model reasons: "I need to query the analytics database"
→ Tool Call: execute_sql("SELECT churn_rate FROM quarterly_metrics...")
→ Observation: {churn_rate: 12.3%, trend: +2.1% vs last quarter}
Iteration 2:
Context: [original query, tool result, new observations]
→ Model reasons: "Churn increased. I should identify top reasons"
→ Tool Call: query_support_tickets("WHERE issue_type='churn'...")
→ Observation: {top_reasons: ["pricing_concerns", "feature_gaps", ...]}
Iteration 3:
Context: [query, both previous results, reasoning]
→ Model reasons: "I have sufficient data to answer. Top driver is pricing."
→ Output: "Churn rate is 12.3%, up 2.1% from last quarter.
Primary driver: pricing concerns (45% of churn-related tickets)."
Automated Reasoning in Loop Control:
The harness employs sophisticated termination reasoning:
def should_continue_iteration(iteration_history, max_iterations, timeout):
"""Automated reasoning about loop continuation."""
# Rule 1: Hard limits
if len(iteration_history) >= max_iterations:
return False, "maximum_iterations_reached"
if elapsed_time() > timeout:
return False, "timeout_exceeded"
# Rule 2: Convergence detection
if has_converged(iteration_history):
return False, "convergence_detected"
# Rule 3: Signal analysis
latest_output = iteration_history[-1]
if "I have sufficient information to answer" in latest_output:
return False, "agent_signaled_completion"
if "I need to" in latest_output:
return True, "agent_requesting_action"
# Rule 4: Information gain analysis
new_info = extract_novel_information(latest_output)
if new_info < 0.05 * context_used: # Less than 5% new information
return False, "diminishing_returns"
return True, "continue_reasoning"
Standard Operating Procedures: Structured Workflows
While agent harnesses provide the runtime infrastructure, Standard Operating Procedures (SOPs) define the behavioral blueprint. Emerging from Amazon's internal builder community, Agent SOPs represent a breakthrough in achieving the "determin-ish-tic sweet spot": structured guidance with intelligent flexibility.

Figure 3: SOP Decision Graph - Transformation of natural language procedures into structured DAG for deterministic agent execution
SOP Architecture and Specification
Agent SOPs employ a standardized markdown format with three core elements:
1. RFC 2119 Constraint Keywords
SOPs leverage keywords from RFC 2119—the Internet Engineering Task Force standard for requirement specifications—to provide precise behavioral control without rigid scripting:
— Automated Reasoning / Neurosymbolic AI come into the picture —
| Keyword | Meaning | Example Use |
| MUST / REQUIRED / SHALL | Absolute requirement | "MUST verify customer identity before processing refunds" |
| SHOULD / RECOMMENDED | Strong recommendation with justifiable exceptions | "SHOULD check inventory before confirming orders" |
| MAY / OPTIONAL | Truly discretionary actions | "MAY provide personalized recommendations" |
These keywords differentiate between compliance-critical steps, best practices, and optional enhancements, enabling agents to reason about priorities while maintaining guardrails.
2. Parameterized Inputs
Rather than hardcoding values, SOPs accept parameters:
## Process Refund Request SOP
**Parameters:**
- {order_id}: The order identifier
- {refund_reason}: Customer-provided reason
- {refund_amount}: Requested refund value
- {payment_method}: Original payment method
**Procedure:**
1. Agent MUST authenticate customer identity
2. Agent MUST retrieve order details for {order_id}
3. Agent SHOULD validate {refund_amount} <= order_total
4. IF fraud_risk_score > 75: Agent MUST escalate to human review
5. ELSE: Agent MAY process refund to {payment_method}
6. Agent MUST log all actions to audit trail
Automated Reasoning Component:
The agent reasons about parameter selection:
def intelligent_parameter_selection(sop, context):
"""Agent auto-fills SOP parameters from context."""
parameters = {}
for param in sop.required_parameters:
# Try multiple inference strategies
# Strategy 1: Explicit mention in query
if param.name in context.query:
parameters[param.name] = extract_value(context.query, param.name)
# Strategy 2: Semantic inference
elif param.semantic_type == "customer_id":
# Agent reasons: User is asking about their account
customer_id = infer_from_context(context.conversation_history)
parameters[param.name] = customer_id
# Strategy 3: Retrieve from recent history
elif param.name in context.previous_values:
parameters[param.name] = context.previous_values[param.name]
# Strategy 4: Query user if ambiguous
else:
ask_user_for_clarification(param.name, param.description)
return parameters
3. Decision Graph Representation
Behind the natural language interface, SOPs are formally represented as directed acyclic graphs (DAGs):
Node Types:
├─ ACTION: Execute operation (call API, update database)
├─ DECISION: Evaluate condition, branch execution
├─ OBSERVATION: Gather information
└─ TERMINAL: End state (success or failure)
Edges:
├─ Sequential: A → B (proceed to next step)
├─ Conditional: A →[IF condition] B, A →[ELSE] C
└─ Parallel: A ⇉ B,C (fan out to multiple agents)
SOP Execution with Automated Reasoning
class SOPExecutor:
def execute(self, sop_graph, initial_state):
"""Execute SOP with automated reasoning at each step."""
current_node = sop_graph.start
observations = initial_state
history = []
while not current_node.is_terminal:
# Automated reasoning: Why this node?
reasoning = self.explain_node_selection(
current_node, observations, sop_graph
)
history.append({
"node": current_node.id,
"reasoning": reasoning,
"state": observations.copy()
})
if current_node.type == "ACTION":
# Execute action with error recovery reasoning
try:
result = self.execute_action(current_node)
observations[current_node.output_name] = result
current_node = current_node.success_edge
except ActionError as e:
# Automated reasoning: How to recover?
recovery = self.reason_about_recovery(
e, current_node, observations
)
if recovery == "RETRY":
current_node = current_node.retry_edge
elif recovery == "ALTERNATE_PATH":
current_node = current_node.alternate_edge
else:
current_node = current_node.failure_edge
elif current_node.type == "DECISION":
# Evaluate condition with uncertainty handling
condition_value = self.evaluate_condition(
current_node.condition, observations
)
# Automated reasoning: Confidence in decision
confidence = self.assess_confidence(
condition_value, observations
)
if confidence > 0.95:
# High confidence - proceed
current_node = (current_node.true_edge
if condition_value else
current_node.false_edge)
else:
# Low confidence - gather more information
current_node = current_node.gather_evidence_edge
return {
"final_state": observations,
"execution_path": history,
"success": current_node.is_success
}
def explain_node_selection(self, node, state, graph):
"""Generate human-readable reasoning."""
return llm.complete(f"""
SOP Step: {node.description}
Current State: {state}
Explain why this step is appropriate and what it accomplishes.
""")
The Determinism Spectrum
Understanding when to apply deterministic versus non-deterministic approaches is critical for production AI systems.

Figure 4: Deterministic vs Non-Deterministic Agents - Understanding the spectrum and the hybrid approach enabled by SOPs
Deterministic Agents
Characteristics:
✓ Same input → same output, always (reproducible)
✓ Rule-based logic with explicit if-then conditions
✓ Fully transparent: every decision traces to specific rules
✓ Auditable: complete explanation of decision pathways
✗ Cannot adapt outside programmed rules
✗ Brittle when requirements change
Enterprise Applications:
Finance: Fraud detection rule execution, transaction approval workflows
Healthcare: Regulatory compliance checklists, medication contraindication screening
Legal: Contract interpretation with fixed legal standards
Manufacturing: Safety-critical control systems requiring guaranteed behavior
Example Deterministic Workflow:
def process_high_value_transaction(transaction):
"""Deterministic transaction validation."""
# Rule 1: Age verification (MUST requirement)
if get_customer_age(transaction.customer_id) < 18:
return {
"decision": "REJECT",
"reason": "Customer under 18",
"rule": "AML_001"
}
# Rule 2: Amount threshold (SHOULD requirement)
if transaction.amount > 10000:
if not customer_has_been_verified(transaction.customer_id):
return {
"decision": "ESCALATE_TO_HUMAN",
"reason": "High amount requires verification",
"rule": "AML_002"
}
# Rule 3: Risk scoring (MAY requirement)
risk_score = calculate_risk_score(transaction)
if risk_score > 80:
return {
"decision": "ESCALATE_TO_HUMAN",
"reason": f"High risk score: {risk_score}",
"rule": "AML_003"
}
# Default: Approve
return {
"decision": "APPROVE",
"reason": "Passed all checks"
}
Non-Deterministic Agents
Characteristics:
✓ Adaptive: learns from data patterns
✓ Creative: generates novel solutions beyond training
✓ Flexible: handles unforeseen scenarios
✓ Nuanced: understands context and subtle variations
✗ Variable outputs for same input
✗ Difficult to fully interpret decisions
✗ Cannot guarantee compliance
Enterprise Applications:
Customer Support: Chatbots handling diverse queries with empathy
Personalization: Recommendation engines suggesting unique product combinations
Content Creation: Marketing copy generation, product descriptions
Analysis: Pattern discovery, hypothesis generation from data
Example Non-Deterministic Workflow:
def generate_personalized_recommendation(customer):
"""Non-deterministic recommendation with LLM reasoning."""
# Gather customer context
purchase_history = get_purchase_history(customer)
browsing_behavior = get_browsing_behavior(customer)
similar_customers = find_similar_customers(customer)
# LLM-based reasoning (variable output)
recommendation = llm.complete(f"""
Customer Profile:
- Purchase History: {purchase_history}
- Browsing Behavior: {browsing_behavior}
- Peers: {similar_customers}
Based on this customer's interests and behavior, what 3 products
would you recommend and why?
Consider: novelty, relevance, cross-sell potential, customer segment trends.
""",
temperature=0.8 # Allow creative variation
)
# Multiple invocations will produce different (but related) recommendations
return recommendation
The Hybrid Approach: "Determin-ish-tic" Systems
Modern production systems strategically combine both paradigms:
class HybridIntelligenceAgent:
"""Combines deterministic controls with non-deterministic reasoning."""
def process_customer_request(self, request):
"""Route to deterministic or non-deterministic handler."""
# Stage 1: Deterministic pattern recognition
known_pattern = self.detect_known_pattern(request)
if known_pattern == "refund_request":
# Known workflow - deterministic SOP
return self.execute_refund_sop(request)
elif known_pattern == "simple_inquiry":
# Structured response - deterministic template
return self.apply_template(request, template="simple_inquiry")
# Stage 2: Intelligent routing for edge cases
else:
confidence = self.assess_routing_confidence(request)
if confidence > 0.95:
# High confidence in classification - deterministic path
return self.route_deterministic(request)
elif confidence > 0.70:
# Moderate confidence - hybrid approach
deterministic_result = self.route_deterministic(request)
enhancement = self.apply_intelligent_refinement(
deterministic_result, request
)
return enhancement
else:
# Low confidence - full reasoning
return self.apply_full_reasoning(request)
Key Insight: SOPs enable this hybrid approach by encoding the routing logic:
MUST clauses enforce deterministic requirements
SHOULD clauses guide probabilistic reasoning with justified exceptions
MAY clauses enable creative exploration within safe boundaries
Production Implementation Patterns
Context Engineering Best Practices
Principle 1: Minimize Context Bloat
# ❌ Anti-pattern: Large results consume precious context
search_results = web_search("AI agent architecture")
# Returns: 50,000 tokens of full articles and metadata
messages.append({"role": "assistant", "content": search_results})
# Cost: 50K tokens gone, only starting reasoning
# ✅ Recommended: Offload to file system
write_file("/workspace/search_results.txt", search_results)
messages.append({"role": "assistant", "content":
"Completed search. Saved results to search_results.txt. "
"Found 3 recent papers on agent architectures (2024-2025), "
"2 industry benchmarks, and implementation guides."
})
# Cost: 200 tokens to describe findings, agent selectively retrieves details
Principle 2: Hierarchical Summarization
def adaptive_summarization(messages, context_limit):
"""Compress old context while preserving new information."""
token_count = sum(count_tokens(m) for m in messages)
if token_count > 0.75 * context_limit:
# Identify critical information to preserve
critical_messages = [m for m in messages
if is_critical(m)]
old_messages = messages[:-20]
recent_messages = messages[-20:]
# Compress old context
summary = llm.complete(f"""
Summarize this conversation focusing on:
1. Key decisions made
2. Important findings
3. Current task status
Messages: {old_messages}
""")
# Reconstruct with compressed history
return [
{"role": "system", "content": summary},
*recent_messages
]
Principle 3: File System as First-Class Memory
Production implementations treat files as structured memory:
class FileSystemMemory:
"""Structured file system for agent memory."""
def __init__(self, workspace_path):
self.workspace = workspace_path
self.create_directory_structure()
def create_directory_structure(self):
"""Organize memory by semantic purpose."""
os.makedirs(f"{self.workspace}/current_task", exist_ok=True)
os.makedirs(f"{self.workspace}/analysis", exist_ok=True)
os.makedirs(f"{self.workspace}/findings", exist_ok=True)
os.makedirs(f"{self.workspace}/context", exist_ok=True)
os.makedirs(f"{self.workspace}/learning", exist_ok=True)
def write_task_plan(self, plan):
"""Store structured task plan."""
content = f"""
# Task Plan
Updated: {datetime.now()}
## Goal
{plan['goal']}
## Steps
{'\n'.join(f"- [ ] {step}" for step in plan['steps'])}
## Dependencies
{'\n'.join(f"- {dep}" for dep in plan['dependencies'])}
"""
self.write_file("current_task/plan.md", content)
def write_findings(self, key, value):
"""Store discovered insights."""
self.append_file("findings/index.json", {
"key": key,
"value": value,
"timestamp": datetime.now().isoformat(),
"confidence": 0.95
})
def retrieve_relevant_context(self, query):
"""Intelligently retrieve stored information."""
# Search for relevance using semantic similarity
results = []
for filepath in self.find_files():
content = self.read_file(filepath)
similarity = compute_similarity(query, content)
if similarity > 0.5:
results.append({
"file": filepath,
"relevance": similarity,
"content": content
})
return sorted(results, key=lambda x: x['relevance'], reverse=True)
Multi-Agent Orchestration Patterns
Pattern: Hierarchical Supervisor with Specialist Workers
class AnalyticsTeam:
"""Multi-agent analytics system with clear specialization."""
def __init__(self):
self.supervisor = Agent(
name="Analytics Supervisor",
system_prompt="""You are the analytics team supervisor. Your role:
1. Understand the user's analytical question
2. Determine which specialists to engage
3. Coordinate their work
4. Synthesize findings into coherent answer
Available specialists:
- Data Analyst: Queries databases, performs statistical analysis
- Visualization Expert: Creates charts, dashboards, visual reports
- Insights Generator: Identifies patterns, generates recommendations
"""
)
self.data_analyst = Agent(
name="Data Analyst",
system_prompt="You are a SQL expert. Query databases and perform analysis.",
tools=[sql_query, statistical_test, load_dataset]
)
self.visualization_expert = Agent(
name="Visualization Expert",
system_prompt="You are a data visualization specialist.",
tools=[create_chart, build_dashboard, export_visual]
)
self.insights_generator = Agent(
name="Insights Generator",
system_prompt="You are an expert at pattern recognition and recommendations.",
tools=[search_industry_benchmarks, generate_recommendations]
)
def analyze(self, user_query):
"""Orchestrate team to answer analytical question."""
# Supervisor routes work
routing = self.supervisor.run(f"""
User Question: {user_query}
Determine:
1. Is data retrieval needed? (→ Data Analyst)
2. Should we visualize findings? (→ Visualization Expert)
3. What actionable insights matter? (→ Insights Generator)
""")
results = {}
if routing.includes("data_analyst"):
results["data"] = self.data_analyst.run(
f"Answer this question: {user_query}"
)
if routing.includes("visualization_expert"):
results["visuals"] = self.visualization_expert.run(
f"Create visualizations for: {results.get('data', user_query)}"
)
if routing.includes("insights_generator"):
results["insights"] = self.insights_generator.run(
f"Identify key insights: {results.get('data', user_query)}"
)
# Supervisor synthesizes
final_answer = self.supervisor.run(f"""
Specialist Results:
{json.dumps(results)}
Create a comprehensive answer that:
1. Directly answers the user's question
2. Provides data-driven support
3. Offers visual evidence
4. Suggests actionable next steps
""")
return final_answer
Evaluation and Observability
Comprehensive Evaluation Framework
Production AI agents require evaluation across multiple dimensions:
class AgentEvaluator:
"""Multi-dimensional agent evaluation system."""
def evaluate(self, agent, test_cases):
"""Comprehensive evaluation across all metrics."""
results = {
"task_performance": {},
"tool_correctness": {},
"efficiency": {},
"safety_compliance": {}
}
for test in test_cases:
trace = agent.run(test.query, record_trace=True)
# Task Performance Metrics
results["task_performance"][test.id] = {
"completion": 1 if trace.success else 0,
"accuracy": compute_accuracy(trace.output, test.expected),
"groundedness": measure_hallucination(trace.output, trace.facts_used),
"clarity": assess_response_quality(trace.output)
}
# Tool Correctness Metrics
results["tool_correctness"][test.id] = {
"selection_accuracy": measure_tool_selection(trace),
"parameter_accuracy": measure_parameter_correctness(trace),
"invocation_sequence": measure_ordering(trace),
"error_recovery": measure_recovery_quality(trace)
}
# Efficiency Metrics
results["efficiency"][test.id] = {
"token_consumption": trace.total_tokens,
"cost": trace.total_tokens * MODEL_COST_PER_TOKEN,
"latency_ms": trace.execution_time,
"iteration_count": len(trace.reasoning_steps),
"tool_calls": len(trace.tool_invocations)
}
# Safety & Compliance Metrics
results["safety_compliance"][test.id] = {
"sop_compliance": measure_sop_adherence(trace),
"constraint_violations": detect_constraint_violations(trace),
"data_privacy": check_pii_exposure(trace),
"bias_detection": assess_fairness(trace),
"explainability": measure_reasoning_transparency(trace)
}
return self.aggregate_results(results)
SOP-Specific Compliance Testing
def validate_sop_compliance(execution_trace, sop_specification):
"""Verify agent adherence to SOP requirements."""
compliance_report = {
"path_accuracy": None, # Did agent follow valid graph paths?
"leaf_accuracy": None, # Did agent reach correct terminal state?
"must_compliance": None, # Were MUST requirements met?
"should_compliance": None, # Were SHOULD guidelines followed?
"overall_score": None
}
# Extract SOP DAG
sop_graph = parse_sop_to_dag(sop_specification)
# Path Accuracy: Validate execution path
execution_path = extract_execution_path(execution_trace)
valid_paths = enumerate_valid_paths(sop_graph)
compliance_report["path_accuracy"] = (
1.0 if execution_path in valid_paths else 0.0
)
# Leaf Accuracy: Validate terminal state
terminal_state = execution_trace.final_state
expected_terminal = sop_graph.terminal_node
compliance_report["leaf_accuracy"] = (
1.0 if validate_state_match(terminal_state, expected_terminal) else 0.0
)
# MUST Requirement Compliance (absolute)
must_requirements = extract_must_clauses(sop_specification)
must_violations = [
req for req in must_requirements
if not verify_requirement_met(req, execution_trace)
]
compliance_report["must_compliance"] = (
1.0 - (len(must_violations) / max(len(must_requirements), 1))
)
# SHOULD Guideline Compliance (strong preference)
should_guidelines = extract_should_clauses(sop_specification)
should_deviations = [
guide for guide in should_guidelines
if not verify_guideline_followed(guide, execution_trace)
]
compliance_report["should_compliance"] = (
1.0 - (len(should_deviations) / max(len(should_guidelines), 1))
)
# Overall Score
compliance_report["overall_score"] = (
compliance_report["path_accuracy"] * 0.3 +
compliance_report["leaf_accuracy"] * 0.3 +
compliance_report["must_compliance"] * 0.25 +
compliance_report["should_compliance"] * 0.15
)
return compliance_report
# Production benchmark targets:
# - Path Accuracy: > 99%
# - Leaf Accuracy: > 98%
# - MUST Compliance: 100%
# - SHOULD Compliance: > 95%
# - Overall Score: > 0.97 (97%)
Automated Reasoning in Agent Systems
The most sophisticated production agents embed meta-cognitive capabilities—the ability to reason about their own reasoning, decisions, and knowledge gaps.
Levels of Automated Reasoning
Level 1: Basic Tool Reasoning
# Agent selects tools based on task requirements
if "churn" in query and "reasons" in query:
call_support_ticket_api() # Get qualitative reasons
call_analytics_database() # Get quantitative data
Level 2: Conditional Procedural Reasoning
# Agent follows conditional procedures
if customer_age < 18:
require("identity_verification")
elif transaction_amount > 10000:
require("manual_review")
else:
proceed_with_processing()
Level 3: Meta-Reasoning About Reasoning Quality
def assess_reasoning_confidence(reasoning_trace, conclusion):
"""Agent evaluates its own reasoning quality."""
factors = {
"evidence_quality": measure_source_quality(reasoning_trace),
"evidence_sufficiency": assess_evidence_coverage(reasoning_trace),
"chain_validity": validate_logical_chain(reasoning_trace),
"alternative_explanations": explore_competing_hypotheses(reasoning_trace),
"assumption_validity": check_assumption_soundness(reasoning_trace)
}
confidence = aggregate_confidence_factors(factors)
if confidence < 0.7:
# Low confidence - request more information
return {
"confidence": confidence,
"action": "gather_more_evidence",
"gaps": identify_evidence_gaps(factors)
}
elif confidence < 0.85:
# Moderate confidence - flag for human review
return {
"confidence": confidence,
"action": "request_human_confirmation",
"reasoning_summary": explain_reasoning(reasoning_trace)
}
else:
# High confidence - proceed
return {
"confidence": confidence,
"action": "proceed_with_conclusion",
"explanation": explain_reasoning(reasoning_trace)
}
Level 4: Self-Improving Reasoning
The most advanced agents update their own decision-making processes:
class SelfImprovingAgent:
def __init__(self):
self.reasoning_strategies = load_strategies()
self.success_log = []
self.failure_log = []
def execute_with_learning(self, task):
"""Execute task and extract learnings."""
# Select reasoning strategy
strategy = self.select_best_strategy(task)
# Execute
result = strategy.execute(task)
# Evaluate
if result.success:
self.success_log.append({
"task": task,
"strategy": strategy.name,
"approach": strategy.reasoning_steps,
"time": result.execution_time
})
else:
self.failure_log.append({
"task": task,
"strategy": strategy.name,
"failure_point": result.failure_location,
"attempted_recovery": result.recovery_attempts
})
# Learn
if len(self.failure_log) > 0 and result.success:
self.extract_and_apply_learnings()
return result
def extract_and_apply_learnings(self):
"""Analyze successes and failures to improve strategy."""
# What strategies work best for different task types?
strategy_effectiveness = self.analyze_strategy_performance()
# What are common failure modes?
failure_patterns = self.identify_failure_patterns()
# How can we avoid failures?
preventive_measures = self.design_preventive_checks(failure_patterns)
# Update strategy selection
for task_type, effective_strategies in strategy_effectiveness.items():
self.reasoning_strategies[task_type] = (
sort_by_effectiveness(effective_strategies)
)
# Add preventive checks
for failure_mode, check in preventive_measures.items():
self.add_early_detection(failure_mode, check)
Reasoning About Uncertainty
Production agents must handle incomplete information gracefully:
class UncertaintyAwareReasoner:
def reason_with_uncertainty(self, evidence, hypothesis):
"""Make decisions despite incomplete information."""
# Estimate confidence
confidence = estimate_confidence(evidence, hypothesis)
if confidence > 0.95:
# High certainty - execute decisively
return {
"decision": "execute",
"confidence": confidence,
"recommendation": hypothesis
}
elif confidence > 0.7:
# Moderate certainty - execute with monitoring
return {
"decision": "execute_with_monitoring",
"confidence": confidence,
"monitoring_criteria": generate_monitoring_criteria(hypothesis)
}
elif confidence > 0.5:
# Low certainty - explore alternatives
alternatives = generate_hypotheses(evidence)
return {
"decision": "gather_more_evidence",
"confidence": confidence,
"alternatives": alternatives,
"next_steps": prioritize_evidence_gathering(alternatives)
}
else:
# Very low certainty - escalate
return {
"decision": "escalate_to_human",
"confidence": confidence,
"reasoning": explain_uncertainty(evidence),
"human_input_needed": what_humans_can_determine(hypothesis)
}
Reasoning About Goals and Subgoals
Complex tasks require hierarchical goal decomposition:
class GoalDecompositionEngine:
def decompose_goal(self, goal, constraints):
"""Break complex goal into achievable subgoals."""
# Analyze goal complexity
complexity = analyze_goal_complexity(goal)
if complexity < 0.3:
# Simple goal - direct execution
return {
"goal": goal,
"subgoals": [goal],
"approach": "direct_execution"
}
# Complex goal - recursive decomposition
subgoals = self.recursive_decompose(goal, constraints)
# Plan execution order
execution_plan = self.plan_subgoal_sequence(
subgoals,
constraints=constraints
)
# Identify dependencies
dependencies = self.identify_dependencies(subgoals)
return {
"goal": goal,
"subgoals": subgoals,
"execution_plan": execution_plan,
"dependencies": dependencies,
"estimated_effort": estimate_total_effort(subgoals)
}
def monitor_goal_progress(self, execution_trace, plan):
"""Track progress toward goal achievement."""
progress = {
"subgoals_completed": count_completed_subgoals(execution_trace),
"total_subgoals": len(plan.subgoals),
"completion_percentage": calculate_completion_percentage(execution_trace),
"on_track": is_on_track(execution_trace, plan.estimated_timeline),
"risks": identify_risks(execution_trace, plan),
"mitigations": suggest_mitigations(identify_risks(execution_trace, plan))
}
return progress
Conclusion and Future Directions
Key Takeaways
Architecture Enables Reliability: Agent harnesses provide the infrastructure for consistent, auditable behavior through sophisticated context management, tool orchestration, and execution control.
Procedures Enable Structure: SOPs encode proven workflows as reusable specifications that work across different AI systems, providing explicit control without rigid scripting.
Hybrid Approaches Deliver Value: The "determin-ish-tic" sweet spot—combining deterministic controls with intelligent reasoning—maximizes both reliability and adaptability.
Automated Reasoning Amplifies Intelligence: Meta-cognitive capabilities enable agents to reason about their own reasoning, assess confidence, and gracefully handle uncertainty.
Observability is Non-Negotiable: Production deployments require comprehensive evaluation across task performance, tool correctness, efficiency, and compliance dimensions.
Future Frontiers
Self-Improving Agents: Agents that automatically refine their own decision procedures based on execution traces will emerge as the next evolution, creating continuous learning systems without model retraining.
Multimodal Orchestration: As agents gain capabilities across text, code, images, and structured data, orchestration patterns will become increasingly critical for coordinating diverse modalities.
Reasoning-Compute Trade-offs: Future systems will dynamically adjust reasoning depth (single-step vs. multi-step vs. exhaustive reasoning) based on task complexity and compute budgets.
Certification and Assurance: Regulatory frameworks requiring formal verification of agent behavior will drive development of provably-safe agent systems with mathematical guarantees.