

AJ - AWS Certified Generative AI Developer - Professional (AIP-C01) Exam Handout
Author: Ayyanar Jeyakrishnan | Exam Duration: 4 Hours | Questions: 85

Search for a command to run...
Author: Ayyanar Jeyakrishnan | Exam Duration: 4 Hours | Questions: 85
No comments yet. Be the first to comment.
Somewhere in your organisation right now, a dashboard is showing a healthy deployment frequency, a stable change failure rate, and a throughput line that ticks gently upward. Leadership is satisfied.

Every organization with procedure-driven back-office operations faces the same invisible problem: knowledge lives in three disconnected silos — training videos, static documents, and SME expertise — w
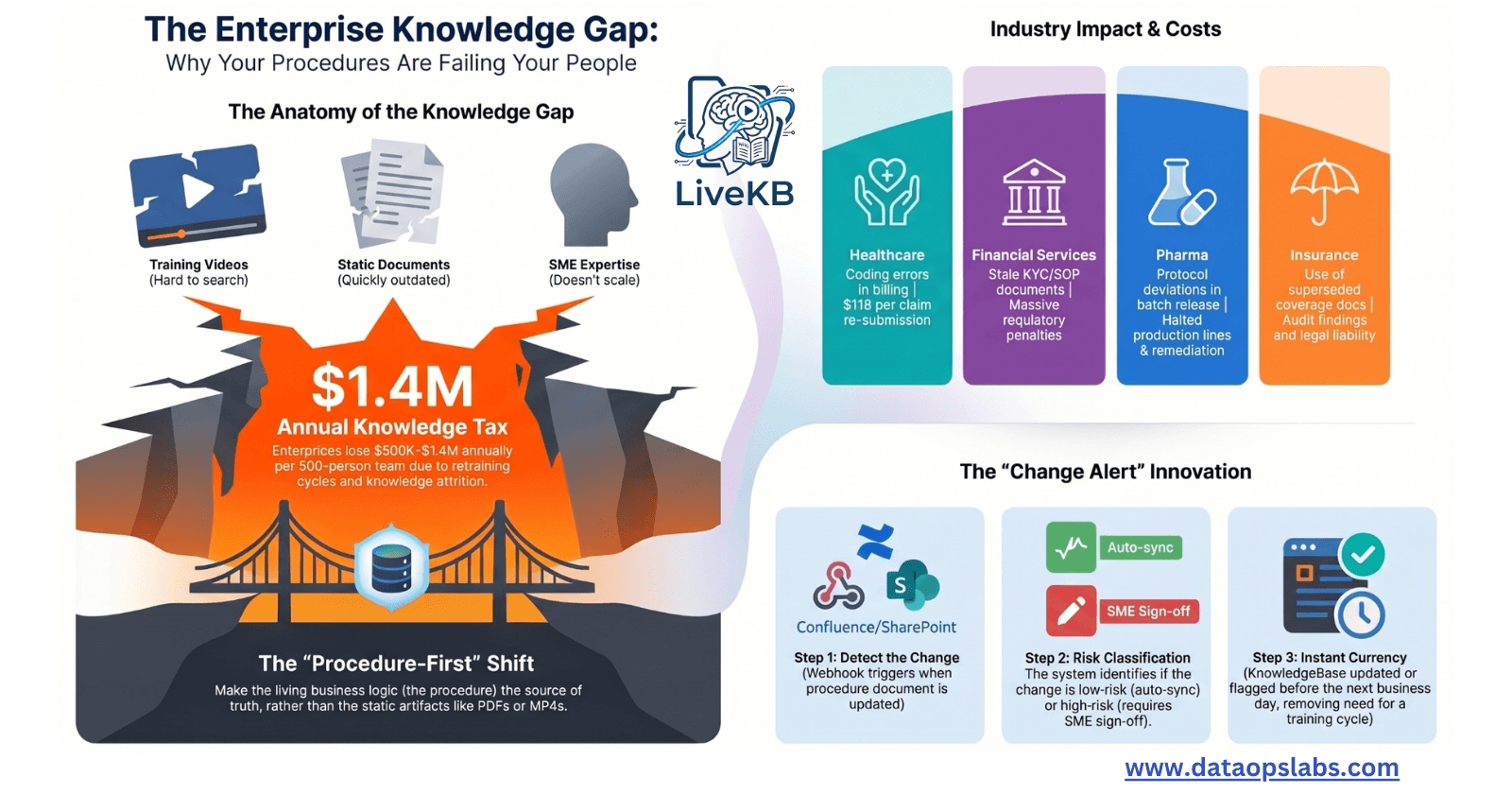
Part 2 of 2 | DataOps Labs Series: Living Knowledge Systems on AWS
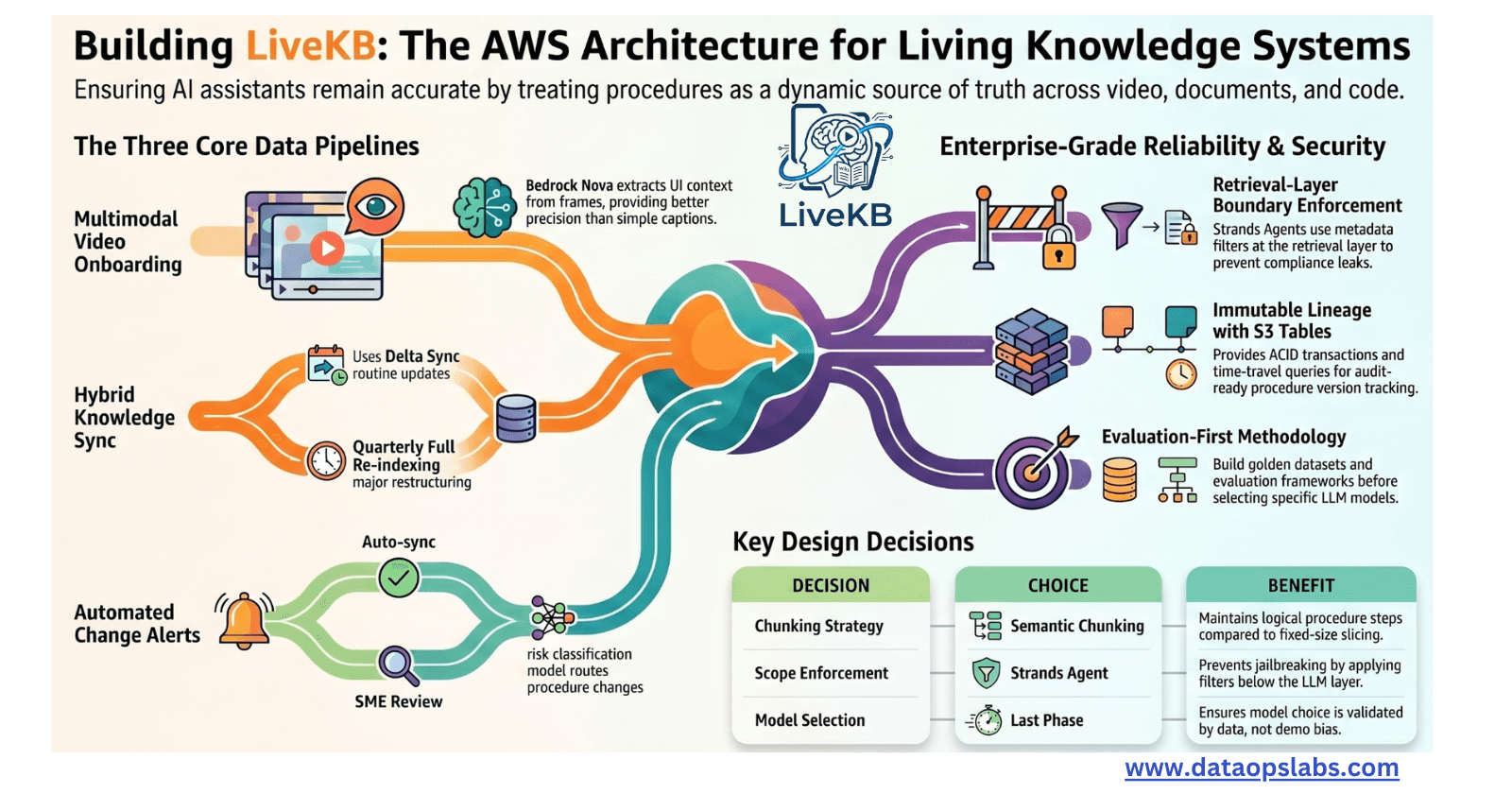
You've tuned your embedding model. You've benchmarked retrieval algorithms. You've swapped LLMs. And your RAG system still gets the wrong answer. Here's what nobody tells you upfront: the bottleneck i
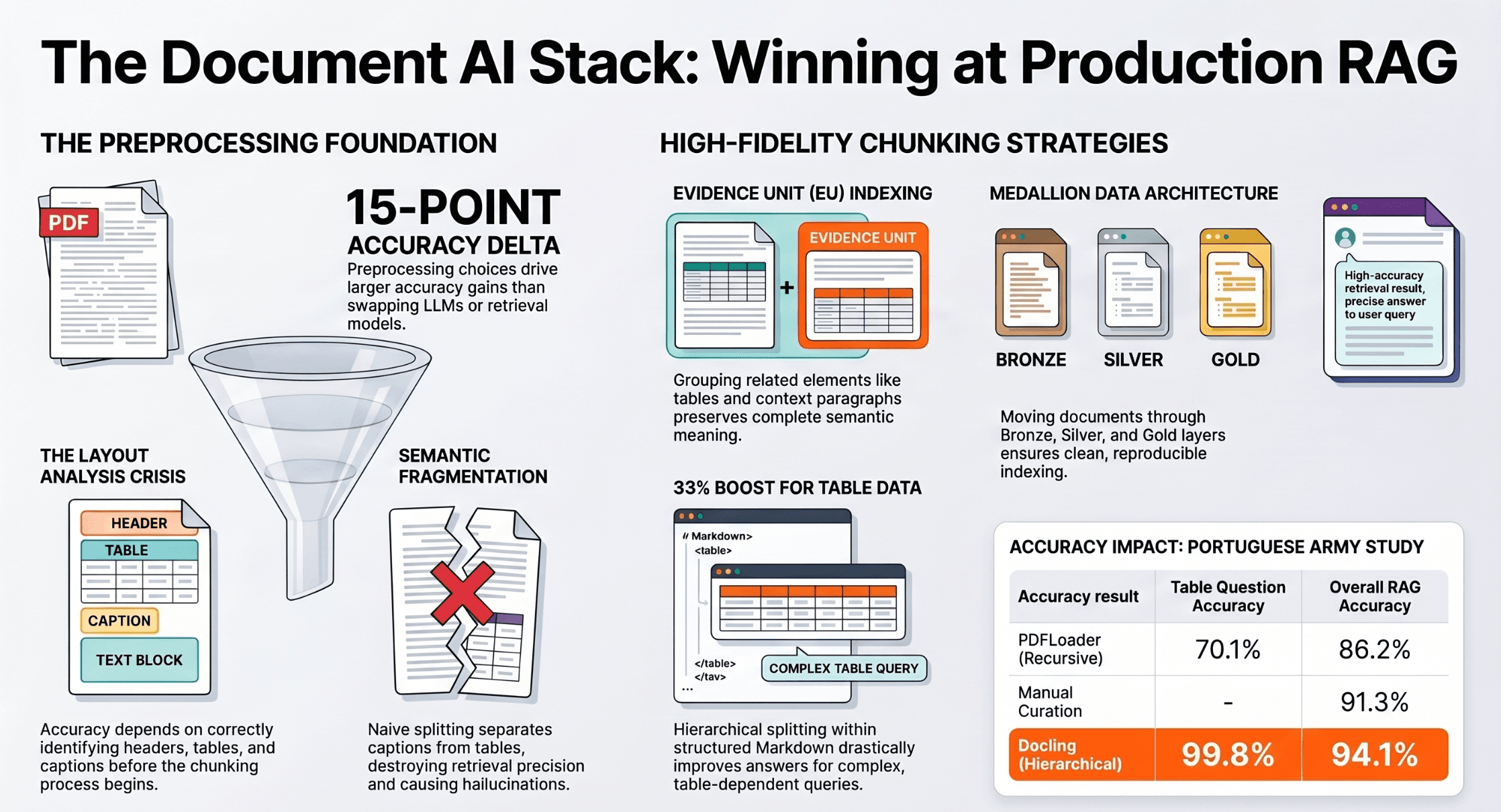
Reasoning and Orchestration (OpenClaw) - Runtime (AWS AgentCore) - Scalable DataLayer (Elastic)

| Attribute | Detail |
|---|---|
| Exam Code | AIP-C01 |
| Duration | 4 hours (240 minutes) |
| Questions | 85 |
| Format | Multiple choice, multiple response |
| Domain |
|---|
| Content Domain 1: Foundation Model Integration, Data Management, and Compliance |
| Content Domain 2: Implementation and Integration |
| Content Domain 3: AI Safety, Security, and Governance |
| Content Domain 4: Operational Efficiency and Optimization for GenAI Applications |
| Content Domain 5: Testing, Validation, and Troubleshooting |
Ref: AWS Certified Generative AI Developer - Professional | Exam Guide PDF
AI-powered code generation, debugging, and transformation
Supports 15+ programming languages
IDE integration (VS Code, JetBrains, AWS Cloud9)
Code security scanning and vulnerability detection
/transform for Java code modernization (e.g., Java 8 to 17)
Enterprise RAG assistant connecting 40+ data sources
Integrations: Salesforce, ServiceNow, SharePoint, Slack, Gmail, Atlassian, MS 365, S3
Permission-aware: Respects ACLs from identity providers
Personalized responses based on IdP data (department, role, etc.)
Q Apps: Convert conversations into lightweight task automation apps (Pro tier)
Plugins: JIRA, ServiceNow, Zendesk, custom OpenAPI plugins
Browser extension: Chrome, Firefox, Slack, Teams, Word, Outlook
Security & Access:
IdP support: Okta, Google Identity, Entra, IAM Identity Center
ACLs ingested from IdP service
All data stays within region; no data used for training
Retrievers:
Native retriever (all integrations)
Existing retriever (Amazon Kendra)
Index provisioning: Enterprise (1M docs, multi-AZ) | Starter (100K docs, single-AZ)
Admin Controls & Guardrails:
Restrict responses to enterprise sources only (or fallback to LLM knowledge)
Topic restrictions, blocked words
Data handling and response generation policies
CloudWatch Metrics: AWS/QBusiness namespace - DocumentsIndexed, ThumbsUpCount, ThumbsDownCount
Natural language to dashboard generation
Business review story generation
Multi-source data unification for insights
Real-time agent assistance for contact centers
Automated response suggestions and knowledge search
Ref: Amazon Q Business | Q Business Features | Q Business Integrations
HIPAA-compliant automatic speech recognition (ASR)
Generates clinical notes from patient-clinician conversations
Extracts structured medical data
Supports clinical documentation workflows
NLP service for text analysis
Entity recognition, sentiment analysis, key phrase extraction
Topic modeling, language detection
Custom entity recognition and classification models
Specialized NLP for healthcare text
Extracts medical entities: medications, conditions, dosages, procedures
HIPAA eligible service
Identifies PHI (Protected Health Information)
ICD-10 and RxNorm ontology linking
This section is heavily tested. Know each technique, when to use it, and how it differs from others.
Ask the model to reason step-by-step before giving a final answer
Most useful for math, logic, and multi-step reasoning
Zero-shot CoT: Add "Let's think step by step" to the prompt
Few-shot CoT: Provide examples with reasoning chains
Combines reasoning (CoT) with tool calls in an interleaved loop
Pattern: Thought -> Action -> Observation -> Thought -> ...
Foundation of the agent loop and deep research patterns
Model reasons about what to do, takes an action (API call, KB search), observes result, then plans next step
Explores multiple reasoning paths simultaneously (branching tree)
Uses search algorithms (BFS/DFS) for systematic exploration
Enables lookahead and backtracking - if one path fails, try another
Best for problems with many possible solutions
Iterative explanation technique inspired by Socratic method
Model generates explanations, then critiques its own reasoning
Goal: do not leave inconsistencies - resolve contradictions
Related to the 5 Whys technique - keep asking "why" to reach root cause
Generate multiple CoT reasoning chains in parallel
Select the most common conclusion across chains
Filters out outlier/incorrect reasoning paths
Effective for ambiguous problems
List subproblems first, then solve from simplest upward
Decompose complex tasks into ordered subtasks
Each solution feeds into the next, building toward final answer
Tell the model to iterate over its own output
Produce initial solution -> Critique it -> Produce improved version
Repeat until quality threshold is met
Provide hints, cues, or keywords in the prompt
Guide the model toward desired output without explicit answers
Useful for steering generation direction
Break tasks into subtasks, chain prompts sequentially
Output of one prompt becomes input for the next
Each step performs a transformation
Example: Extract -> Summarize -> Translate -> Format
Ref: Prompt Engineering Guide | Chain-of-Thought Prompting | Prompt Chaining
| Method | Use Case |
|---|---|
| Bedrock Model Evaluation | Batch dataset, detailed scores across metrics |
| Playground Compare | Single prompt, two models side-by-side, token controls, latency |
Version control for prompts - track changes, audit trail
A/B testing across prompt versions
Parameterized templates - reusable prompts with variables
KMS encryption for prompt security
Drag-and-drop visual builder for GenAI workflows
Connect: Knowledge Bases, Prompts, Lambda functions
Example flow: [User Input] -> [KB Search] -> [LLM Processing] -> [Output]
| Framework | Best For |
|---|---|
| LangChain | Chatbots, agents, chains, tool integration |
| LlamaIndex | Data retrieval, processing, RAG pipelines |
{
"message": { "role": "assistant", "content": [...] },
"stopReason": "end_turn",
"usage": { "inputTokens": X, "outputTokens": Y }
}
Unified structure regardless of model used (no model-specific formatting)
Supports: tools, guardrails, system prompts, text + image
Temperature, topP, maxTokens controls
Use try-catch blocks for error handling
| Error | Root Cause |
|---|---|
| Service Quota Exceeded | Account limits reached |
| ThrottlingException | Too many requests per second |
| Data Issues | Training/validation/output data problems |
| Token Count Exceeded | Input or output too long |
| Malformed Input | Doesn't match model's expected format |
| Internal Server Errors | AWS-side issues |
Ref: Amazon Bedrock | Converse API
Prompt Engineering & RAG fall short?
|
Yes --+-- Need domain knowledge? --> Continued Pre-Training (CPT)
|
+-- Need task-specific skill? --> Fine-Tuning
|
+-- Need smaller/cheaper model? --> Distillation
Input: Small, labeled dataset (prompt-completion pairs)
Pros: Quick, cheap, small data requirements
Cons: Easy to overfit!
Use cases: Sentiment analysis, text summarization, chatbots, classification
| Technique | Description |
|---|---|
| LoRA | Train a small subset of parameters via low-rank matrices |
| QLoRA | LoRA + quantization for memory efficiency |
| Prefix Tuning | Add trainable parameters to input layer |
| Prompt Tuning | Inject learnable soft prompts on input |
| P-Tuning | Automated prompt training with neural networks |
| RLHF | Reinforcement learning from human feedback |
| Multi-task Fine-tuning | Train on multiple tasks simultaneously |
Input: Large, unlabeled domain-specific corpus
Extends model's foundational knowledge
Use cases: Scientific papers, legal documents, financial reports, news articles
Transfer knowledge from teacher model (large) to student model (small)
Example: Llama 70B -> Llama 8B
Sources: Custom prompts, prompts + completions, or invocation logs
Fine-tuning with labels generated by teacher model
Recommended for specific domains
| Metric | Description |
|---|---|
step_number |
Single pass of training batch |
epoch_number |
All steps per epoch |
validation_loss |
Lower = model better fits validation data |
validation_perplexity |
How well model predicts token sequences (lower = better) |
Ref: Bedrock Fine-Tuning | CPT | PEFT Techniques Blog
| Option | Details | Savings |
|---|---|---|
| On-Demand | Pay per token, no commitment | Baseline |
| Provisioned Throughput | Purchase Model Units (MU), hourly rate | 40-60% savings |
| Batch Inference | Queue jobs for async processing | ~50% savings |
| Cross-Region Inference | Route to other regions for capacity | No extra data transfer charges |
1 MU = X input tokens + Y output tokens per minute (model-dependent)
Commitment: 1 month, 6 months, or no commitment
Burst capacity covered by on-demand
Per region only - does not work with cross-region inference
Same price as on-demand in primary region
No extra charges for data transfer
Logs remain in source region
CloudWatch and CloudTrail record in source region
| Metric | Use |
|---|---|
Invocations |
Track usage volume |
InvocationLatency |
Detect performance degradation |
ClientErrors |
Prompt/UI issues |
ServerErrors |
Stability, capacity issues |
InputTokenCount / OutputTokenCount |
Cost monitoring |
Throttles |
Key indicator you need Provisioned Throughput |
Set up in Bedrock console for all models in account
Destinations: S3, CloudWatch Logs, or both
Options for PII masking
Use for: Auditing, pattern analytics, troubleshooting (CW Logs Insights)
InvokeModel, InvokeFlow
InvokeAgent
RetrieveKB
UseGuardrail
Integrate with GuardDuty for threat detection
Performance:
Establish baseline metrics (2-week observability period recommended)
Proactive alerting on deviations (e.g., 5% error increase in 5 minutes)
Track model-specific metrics: coherence, perplexity
Monitor usage against quotas and throttling
Cost:
Invocation logs for usage patterns
Optimize prompts to reduce token usage
Cost allocation tags + budgets + anomaly detection
Consider batch inference for non-real-time workloads
Security:
Audit API access via CloudTrail
GuardDuty for automated threat scans
Monitor CW Logs for PII exposure
Enforce compliance with Guardrails + AWS Config
Ref: Cross-Region Inference | Bedrock Monitoring | Invocation Logging
KB Params: Name, description, tags, IAM role, query engine, log deliveries (NOT inference logging)
Data Source Params:
Name, location (S3 URI - must be in same region)
Parsing strategy: Text | Foundation Model | Data Automation
Chunking strategy (semantic, fixed-size, hierarchical)
Transformation Lambda for custom chunking/metadata
Embedding model + vector store selection
| Setting | Options |
|---|---|
| Search Type | Semantic or Hybrid (text + semantic) |
| Max Results | Configurable |
| Inference Params | Temperature, top-p, top-k, max tokens |
| Prompt Template | System prompt customization |
| Guardrails | Attach guardrail ID |
| Reranking | Improve relevance ordering |
Query is translated into SQL for structured data sources
Natural language to SQL generation
High quality data - clean, well-structured documents
Chunking strategy - align with your query patterns
Feedback loops from users for continuous improvement
KB evaluation - use LLM-as-a-judge
Plan for scalability - monitor index growth
Responsible AI - regular audits for biases, relevance, accuracy
Logging - S3, CW Logs, Firehose
UX - clear UI, fast response time, multimodal support
Use reranking to improve result relevance
| Category | Metrics |
|---|---|
| Query | Answer Relevancy - is input related to documents |
| Retrieval | Context Precision, Context Recall, Context Entity Recall |
| Generation | Faithfulness, Correctness, Coherence |
| Overall | Completeness, Harmfulness, Answer Refusal, Stereotyping |
Faithfulness - answers grounded in retrieved context (hallucination detection)
Relevancy - answers address the question, no redundancy
Precision - relevant docs ranked higher
Recall - all relevant context retrieved vs ground truth
Entity Recall - entities in context vs ground truth
Answer Similarity - semantic comparison of answer vs ground truth
Diverse question sets covering various topics
Balance automatic and human evaluation
Iterative improvement: adjust chunking, reranking strategies
Domain-specific metrics
Regular re-evaluation as Knowledge Base grows
Ref: Bedrock Knowledge Bases | RAG Evaluation | KB How It Works
BUILD-TIME (Setup) RUNTIME (Execution)
+-----------------------+ +---------------------------+
| Select FM | | Pre-process |
| Write Instructions | ------> | Validate user input |
| Attach Action Groups | | Orchestrate |
| Connect KBs | | Think -> KB -> Actions |
+-----------------------+ | Post-process |
| Format response |
+---------------------------+
User sends input/query
FM receives input + context + system prompt
FM breaks down input into sequence of steps
For each step: execute API or query KB
Based on results, plan next action
Output final answer
Customize pre-processing, orchestration, post-processing prompts
Parse using Lambda for dynamically changing prompts
Keep prompts: clear, concise, aligned with agent's capabilities
Multiple can be attached per agent
Max 3 functions per group
Lambda handler pattern:
agent = event["agent"]
actionGroup = event["actionGroup"]
function = event["function"]
params = {p["name"]: p["value"] for p in event["parameters"]}
session = event["sessionAttributes"]
Tune: temperature, topK, length penalty
Customize advanced prompts (pre/post-processing, orchestration)
Continuous monitoring + user feedback
Track conversational metrics
Open-source framework from AWS for building production-ready agents
Three core components: Model Provider, System Prompt, Toolbelt
Native integration with Bedrock Guardrails, KBs, and AgentCore
MCP (Model Context Protocol) support
Observability with OpenTelemetry
| Aspect | Strands SDK | Bedrock Agents |
|---|---|---|
| Control | Complete control of architecture | Managed, serverless |
| Configuration | Code-based | Console-based |
| Deployment | Self-managed or AgentCore | Fully managed |
| Flexibility | Maximum customization | Opinionated patterns |
| Multi-agent | Graph, Swarm, Workflow patterns | Built-in multi-agent collaboration |
Quality assurance and performance benchmarking
Bias detection and fairness assessment
Comparative analysis (models or versions)
Continuous improvement guidance (training, fine-tuning)
Trust and transparency for stakeholders
Regulatory compliance (EU AI Act)
Resource optimization (is the model too large? need fine-tune?)
| Type | Description |
|---|---|
| Automatic (Programmatic) | Predefined metrics: accuracy, robustness, toxicity |
| Model-as-a-Judge | Select metrics and judge model; tasks: text gen, summary, QA, classification |
| Human-Based | Customized UI, form teams, flexible subjective evaluation |
| Metric | What It Measures | Scale |
|---|---|---|
| Perplexity | How well model predicts completion | Lower = better (10 means 10 uniform tokens) |
| BLEU | Translation quality | 0-1 (1 = perfect match) |
| ROUGE-n | N-gram overlap between prediction and reference | 0-1 (1 = best) |
| Coherence / Fluency | Logical flow of output | May need human eval |
| BERTScore | Semantic similarity | Higher = better |
| Task | Metrics |
|---|---|
| QA | Exact Match, F1 |
| Classification | Accuracy, Precision, Recall, F1 |
| Translation | BLEU |
| Summarization | ROUGE |
| Dataset | Use Case |
|---|---|
| TriviaQA | Question Answering |
| Natural Questions | Question Answering |
| WikiText 2 | Robustness |
| Real Toxicity | Toxicity detection |
| Gigaword | Summarization |
| E-Commerce Clothing Reviews | Text Classification |
Define metrics with descriptions and rating methods
Thumbs up/down
Likert scale (5-star)
Freeform feedback (text field)
Number of workers per prompt
Setup CORS in S3
Team via SageMaker GroundTruth private workforce (Cognito or OIDC)
Optional SNS notifications for new tasks
Overview dashboard: Aggregate scores, rating distribution
Inter-rater agreement: Consistency across workers
Sample analysis: Individual samples with ratings
Comparative: Between models, human vs automatic
Action items: Prompt refinement, fine-tuning, bias mitigation
Faithfulness - detect hallucinations
Relevancy - penalize redundancy, incomplete answers
Context Precision - relevant documents ranked higher
Context Recall - context retrieved vs ground truth
Context Entity Recall - entities retrieved vs ground truth
Answer Similarity - semantic comparison vs ground truth
Correctness - accuracy of answer vs ground truth
No ground truth for creative tasks
Contextual dependency and subjectivity
Difficulty evaluating ethics and biases
Factual accuracy (hallucinations)
Consistency across interactions
Adversarial robustness
Need for new evaluation datasets as LLMs improve
Ref: Bedrock Evaluations | Evaluation Metrics | Model Evaluation Blog
No prompts or responses are used to train models
Separate deployment accounts per model provider per region
Provider isolation: Anthropic can't read prompts; Llama hosted separately from Claude
TLS in transit
VPC Endpoints with private IPs
KMS encryption for: prompts, custom models, guardrails
Fine-grained policies
Service roles for Bedrock, agents, KBs
Logging and monitoring (CloudTrail, CloudWatch)
SOC, ISO, HIPAA, GDPR
| Feature | Description |
|---|---|
| Content Filtering | Block harmful, offensive content by category and severity |
| Denied Topics | Define off-limits subjects |
| Word Filters | Block specific words and phrases |
| PII Detection | Identify and redact personally identifiable information |
| Contextual Grounding | Check response faithfulness to source material |
| Automated Reasoning Checks | Mathematical logic to verify factual accuracy (up to 99%) |
Uses formal logic (not statistical methods) to detect hallucinations
Suggests corrections and highlights unstated assumptions
Validates AI responses against defined business rules
Critical for regulated industries (finance, healthcare, legal)
Currently in detection mode
Apply to Bedrock models, agents, and KB responses
Synchronous mode: scans before response (adds latency)
Asynchronous mode: scans in parallel to streaming (small risk of brief inappropriate content)
Ref: Bedrock Guardrails | Automated Reasoning Checks | Responsible AI Blog
Task Requirements Analysis
|
+-- No external data needed? --> Prompt Engineering
|
+-- Need external/real-time data? --> RAG + Knowledge Bases
|
+-- Domain-specific knowledge? --> RAG + PEFT Fine-Tuning
|
+-- Real-time actions needed? --> Agents + Streaming
|
+-- External API integration? --> Agents with Action Groups
Bedrock Intelligent Prompt Routing: Single family routing (e.g., Llama big + small)
Custom Router: LangChain or Lambda-based
Reduces time-to-first-token for users
Works with Amazon Connect for voice AI
Response caching improves repeated query performance
Synchronous: Adds latency, scans before delivery
Asynchronous: Scans in parallel, small risk of brief inappropriate content
Optimize prompts first - clarity, minimize output, specify format precisely
Provisioned Throughput - 40-60% savings for steady workloads
Batch Inference - 50% savings for non-real-time
Prompt caching - reduce redundant computation
Model routing - send simple queries to cheaper models
Define SLAs for response time, latency, alerting
Autoscaling based on CPU, memory, request queue size
Multi-level caching: app-level, response, query results
Monitor cache hit ratio
Load balancing across endpoints
Select model closest to your use case
Consider cost, size, performance, licensing
Use multi-model endpoints and autoscaling
Spot training for cost savings
A/B testing with SageMaker Experiments
SageMaker Pipelines for end-to-end workflows
Feature Store for feature management
Version control for all models
Testing framework: Unit, integration, performance + AI-specialized tests
Human evaluation and A/B testing
Error tracing and user feedback collection
Content moderation and bias detection
Output validation against expected formats
| Item | Value |
|---|---|
| Exam passing score | 750/1000 |
| Max action group functions | 3 per group |
| Q Business Enterprise index | 1M docs, multi-AZ |
| Q Business Starter index | 100K docs, single-AZ |
| Q Business index unit | 20K documents |
| Provisioned Throughput savings | 40-60% vs on-demand |
| Batch inference savings | ~50% vs on-demand |
| Baseline monitoring period | 2 weeks recommended |
| Automated Reasoning accuracy | Up to 99% |
| BLEU perfect score | 1.0 |
| ROUGE perfect score | 1.0 |