LiveKB: Your Procedures Are Lying to Your People — The Knowledge Gap Nobody Measures
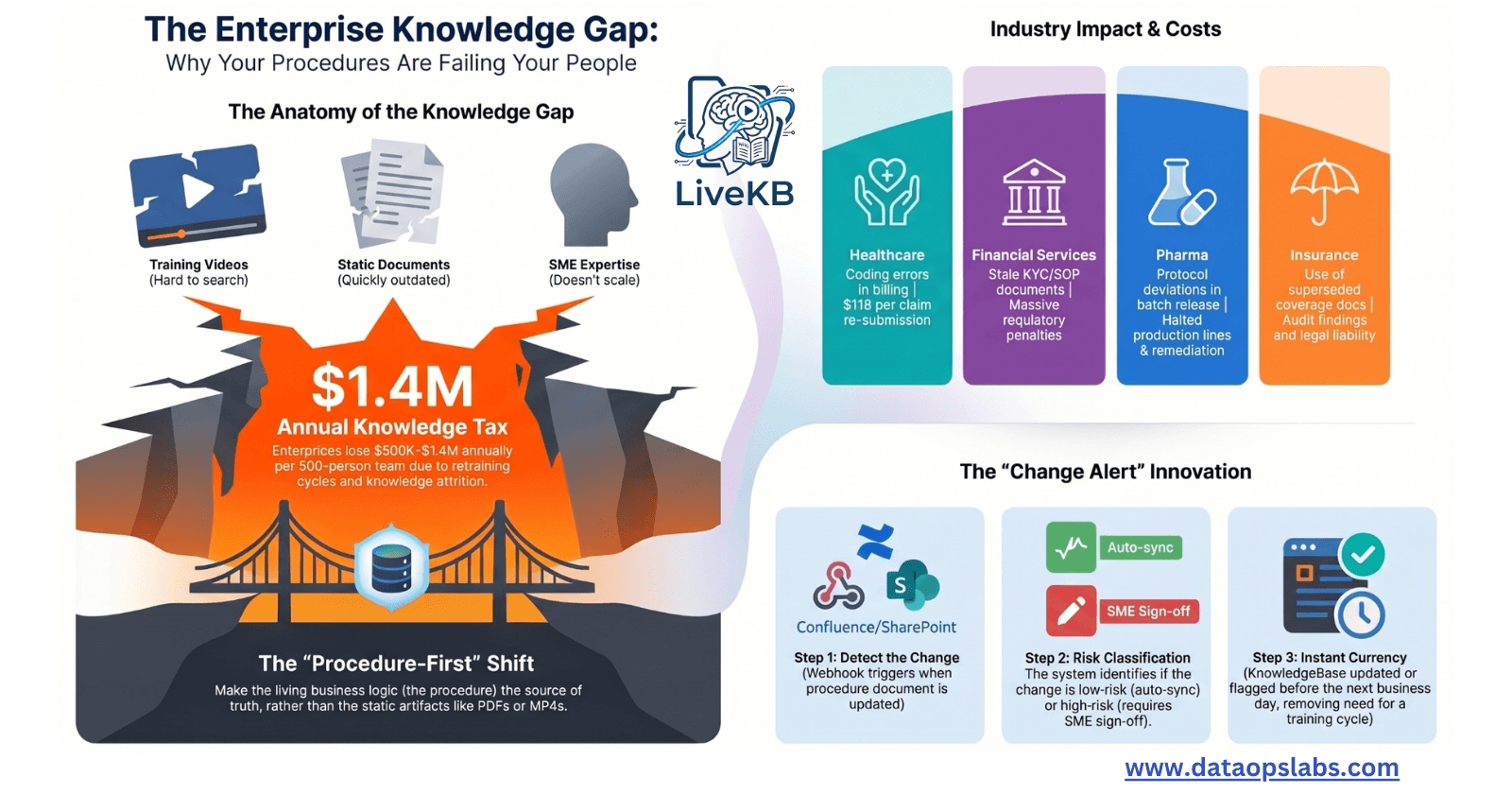
Every organization with procedure-driven back-office operations faces the same invisible problem: knowledge lives in three disconnected silos — training videos, static documents, and SME expertise — with no intelligent layer joining them when an employee needs an answer. Every procedure change triggers a costly retraining cycle. By the time the last person is retrained, the first person's knowledge is already aging.
This post diagnoses the problem in depth, across healthcare, financial services, insurance, pharma, and manufacturing. It introduces the architecture insight that changes everything: making the procedure the living source of truth — not the video, not the document. And it walks through the end-to-end value stream of what that looks like in production.
Part 2 covers the full AWS architecture: Bedrock multimodal, S3 Tables, OpenSearch Serverless, AgentCore, the Strands Agent pattern (deployed on Bedrock AgentCore Runtime), the Change Alert Pipeline, and the production playbook.
The Failure That Repeats Everywhere
It plays out the same way across industries. The names change. The procedures change. The outcome doesn't.
In a hospital billing department, a coder who completed two days of ICD-11 transition training cannot reconcile a denial code she hasn't seen before. The reference guide is 340 pages. The training video is 78 minutes with no chapter navigation. She escalates to a senior coder. He answers — for the fortieth time this quarter.
In a financial services back-office team, an analyst who passed KYC induction last week faces an exception flag on a Type-3 vendor invoice. The Confluence SOP was last updated 14 months ago. The LMS has no searchable chapters. She messages her team lead. He stops what he's doing and answers — again.
In a pharmaceutical operations center, a regulatory affairs coordinator runs a batch release process for the first time since a protocol update. The updated SOP lives in a SharePoint folder she hasn't been notified about. She finds the old version and proceeds. The audit catches it three weeks later.
In a global insurance claims center, a newly trained adjuster encounters a coverage exclusion scenario not explicitly covered in the onboarding module. She finds three different answers in three different documents — all with different dates, none marked as superseded.
💡 The pattern: Every one of these failures shares the same root cause. Knowledge lives in three disconnected silos — video recordings, static documents, and SME expertise — with no intelligent layer joining them at the moment of operational need. The employee was trained. The procedure changed. Nobody told the knowledge system.
The Industries with This Problem
This is not a niche issue. Every sector with regulated, procedure-driven back-office operations has it:

⚠️ These estimates are conservative. In healthcare revenue cycle, the error remediation line alone averages $118 per claim re-submission at scale. In financial services, a single compliance breach attributable to a stale procedure can trigger regulatory penalties orders of magnitude larger than the training cost itself. In pharma, one audit finding from a protocol deviation can halt a batch release line — the cost is not in the finding, it's in the remediation.
Anatomy of the Knowledge Gap: Three Silos, One Missing Layer
Every organization we have studied has invested in at least two of these three systems. Most have all three. None of them talk to each other at the moment an employee needs an answer.

The core failure is subtle but devastating: all three silos treat the video or document as the source of truth. They are not.
The source of truth is the procedure — the living business logic that describes how regulated work must be performed. The procedure changes. The video doesn't update itself. The Confluence page lags by weeks. The SME is the only entity with the current answer — and the SME doesn't scale.
Why Every Existing Tool Fails
Organizations have spent significant capital on tools that are supposed to solve this. None of them do — not because they are badly built, but because each solves a different problem than the one that actually matters.

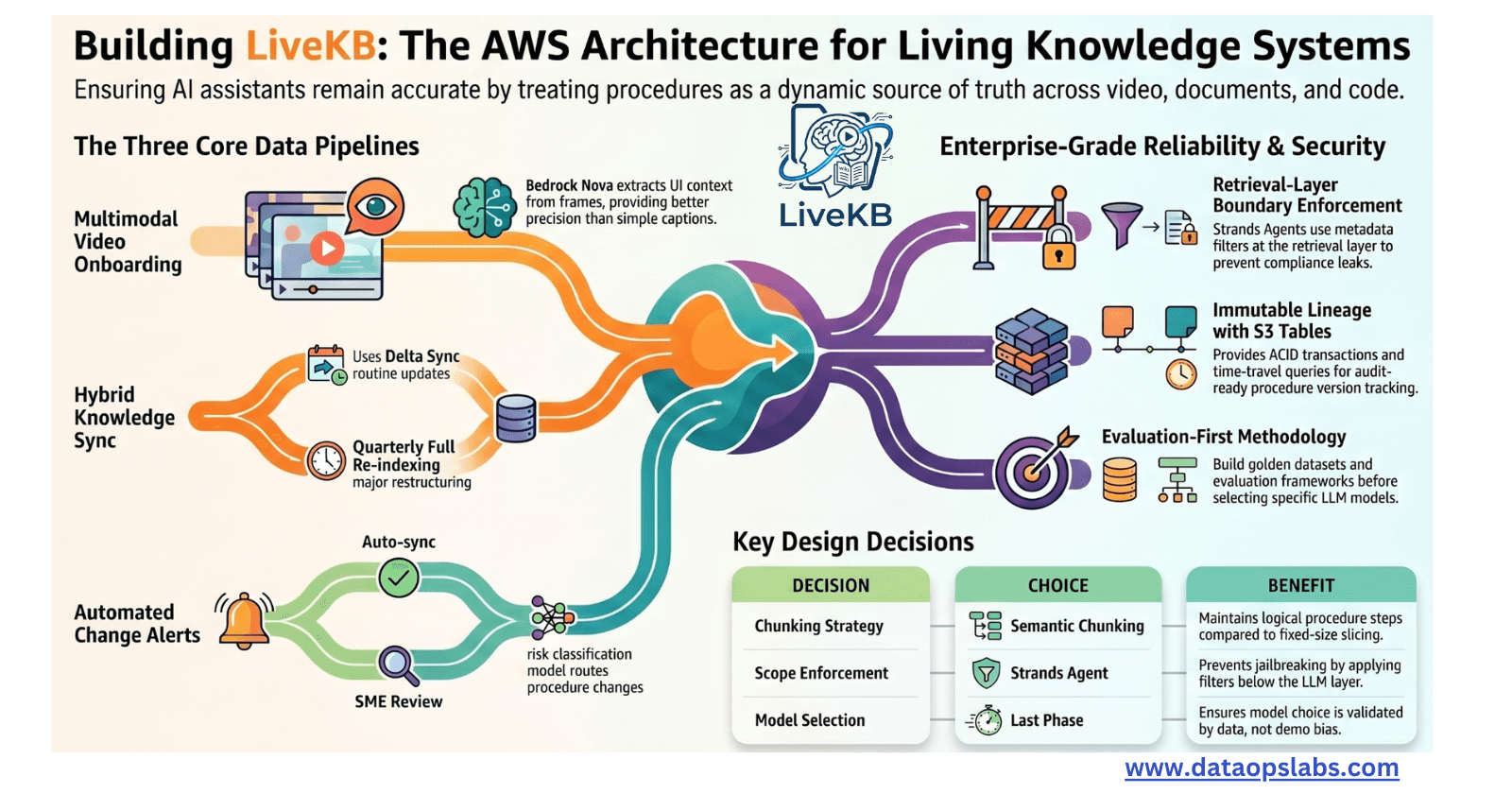
The Architecture — Overview
The system is built on five layers and three pipelines, all running on AWS.

The Three Pipelines
Pipeline 1 — Video Onboarding
A training video enters the system once. Amazon Transcribe generates a timestamped transcript. Bedrock multimodal (Nova) analyzes video frames to map visual procedure steps — UI walkthroughs, diagrams, screen recordings — to their timestamps. Chunks are embedded and indexed into the domain KnowledgeBase. S3 Tables stores the structured metadata: video_id, domain_id, procedure_version, chunk_id, timestamp_range. This work is done once, at ingestion. It is not repeated per employee.
Pipeline 2 — Knowledge Sync
Confluence pages, SharePoint SOPs, and Wiki entries are crawled continuously by Bedrock KnowledgeBase native connectors and custom Lambda functions. When content changes, only the delta is re-embedded and upserted into the OpenSearch Serverless vector index — no full rebuild. The index is always current without manual intervention. The procedure_version field is bumped in S3 Tables with every sync.
Pipeline 3 — Change Alert (the core innovation)
When a procedure document is updated in Confluence, a webhook fires an EventBridge event. A Change Detector Lambda computes the diff between procedure versions. It identifies which video_ids and domain KnowledgeBases are affected. Then it makes a routing decision:
Auto-sync for low-risk wording changes: delta re-embedded immediately, index updated overnight
SME review queue for high-risk or regulated changes: SNS notification to domain SME, index flagged as "pending review", employees see a banner: "This procedure was recently updated — SME review in progress"
🎯 Why this matters: Not all procedure changes carry the same risk. A wording clarification in a billing runbook can auto-sync. A change to an FDA-regulated batch release protocol requires sign-off before the index updates. The system is configurable per domain and regulatory tier. This is what production-ready looks like in regulated environments.
The Value Stream: One Employee, One Question, End-to-End
The value stream below is industry-agnostic. It works identically whether the employee is a KYC analyst in Bengaluru, a claims adjuster in Ohio, a regulatory coordinator in Frankfurt, or a billing coder in Manila. The content of the procedure changes. The architecture doesn't.
The SME never got the message this time. He spent that hour doing the work only he can do.

Why This Can't Be a Demo
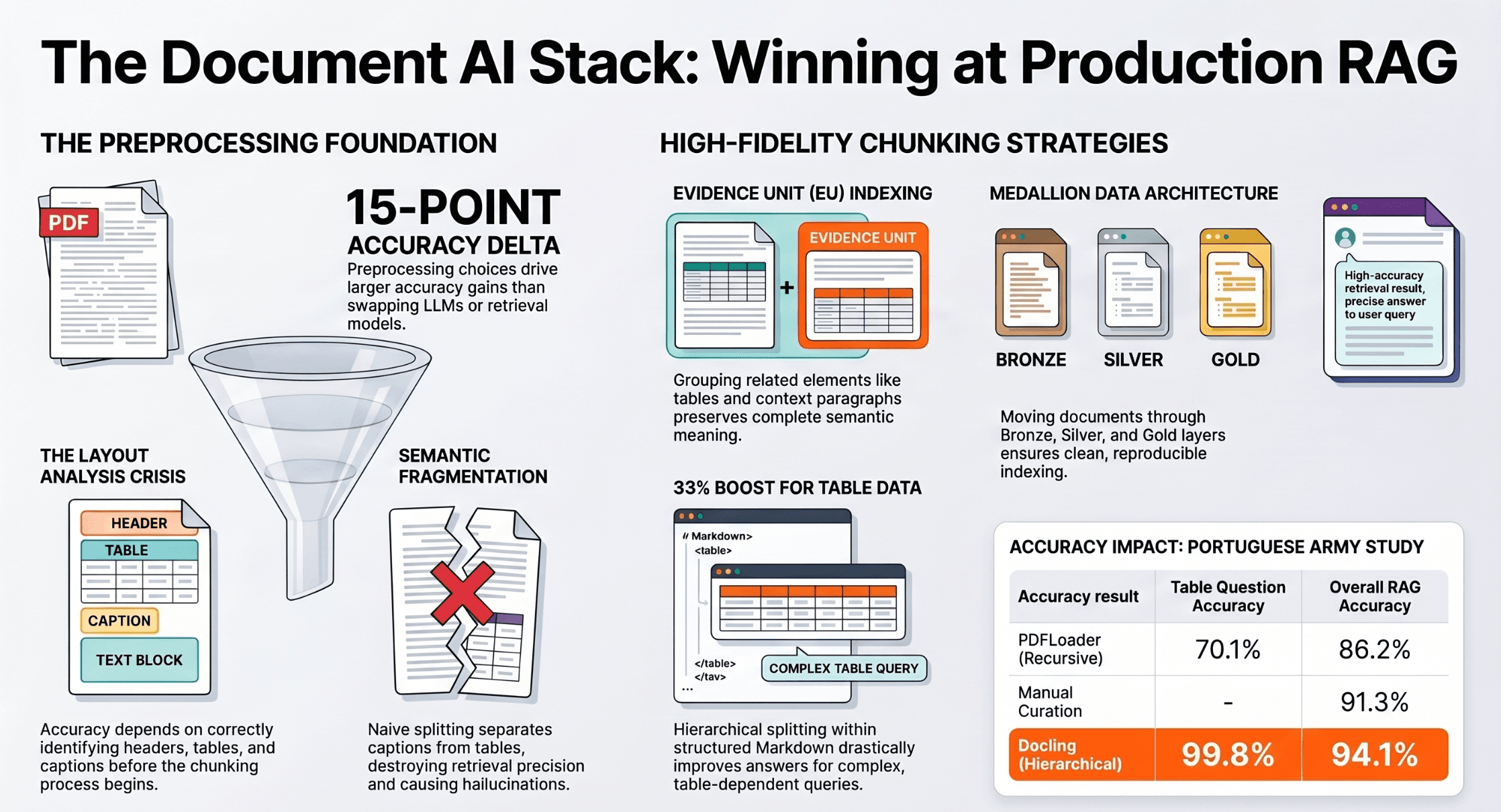
This is where most enterprise GenAI projects fail. A single agent with a good prompt and a RAG pipeline works impressively in a proof of concept. Then you scale it — from one domain to twelve, from 10 users to 5,000, from a stable document corpus to a living procedure base that changes weekly — and the system collapses.
Not because the AI failed. Because the architecture wasn't built for what multi-agent systems require at production scale.
🔴 From a real production failure: In a financial services multi-agent deployment, a credit score agent updated a customer record to 750. A caching layer between agents was not invalidated. 500ms later, the risk assessment agent read the stale score (680). 20% of decisions returned incorrect risk ratings. The LLM performed correctly. The distributed systems architecture did not. Multi-agent systems fail due to bad architecture — not bad AI. This pattern appears identically across healthcare, insurance, and manufacturing deployments.
For the living knowledge system to work in a regulated enterprise environment, five non-negotiable production pillars must be in place

Part 2 goes deep on all five — full implementation architecture, the Strands Agent pattern (deployed on Bedrock AgentCore Runtime), the evaluation framework design, failure patterns from staging, and the production deployment playbook.
The Bigger Thesis: This Is a Compliance Infrastructure
The deeper implication of this architecture only becomes visible when you view it through a regulatory lens.
In any industry where back-office procedures are governed by external regulation — HIPAA, FDA 21 CFR Part 11, Basel III, Solvency II, ISO 13485, DPDP, GDPR — the question "did this employee follow the correct procedure?" is not just an operational question. It is a legal one.
Today, answering that question requires manual evidence gathering: pull training records, find the procedure version in effect on the date in question, hope the employee recalls which version they were trained on, cross-reference against the action taken. This process is slow, expensive, and unreliable.
The living knowledge system changes this. Every answer is cited. Every session log records which procedure version was in effect at query time. Every procedure change is versioned with a timestamp and a diff. When an auditor asks "what did your employee know, and what procedure were they following on March 14th?" — the system answers in seconds, not weeks.
For organizations in regulated environments, this transforms the product from a training efficiency tool into a compliance infrastructure. And that changes the procurement conversation entirely.
What Part 2 Covers
Part 2 is the full Level 400 architecture deep-dive. Everything named in this post — built, deployed, and production-validated: - https://blog.dataopslabs.com/livekb-dataopslabs-part2-by-aj
Bedrock multimodal ingestion — S3 Tables schema for procedure lineage tracking
Per-domain KnowledgeBase on OpenSearch Serverless — chunking strategy tradeoffs
The Strands Agent pattern — built with Strands Agents SDK, deployed on Bedrock AgentCore Runtime — boundary enforcement at the retrieval layer, not the prompt layer
Change Alert Pipeline — EventBridge → diff computation → auto-sync vs. SME-review decision tree
AgentCore Runtime deployment — Strands Agent as ARM64 container, ADOT auto-instrumentation, AgentCore Memory + Identity
Bedrock Evaluation — golden dataset design, 3-layer assessment (deterministic, semantic, behavioural)
Production playbook — why model selection is always last, never first
3 staging failure patterns — what broke, why, and what we changed
🔔 Follow DataOps Labs on Hashnode for the full series and deep-dive walkthroughs.
Key Takeaways
The problem is universal — healthcare, BFSI, insurance, pharma, manufacturing, and GCCs all have it. High-volume, procedure-driven back-office work is the category. The industry is the detail.
The cost is larger than anyone measures — $83K–$235K per retraining cycle × 6 cycles/year × attrition-driven re-induction = a training tax that never appears on a single budget line but eats 7-figure value annually at scale.
Existing tools solve the wrong problem — LMS solves delivery. Wikis solve storage. Chatbots solve Q&A. None solve currency — keeping the knowledge current when the procedure changes.
The insight is architectural, not technological — make the procedure the living source of truth. The video, the document, and the assistant are all renderings of it. When the procedure changes, everything updates. No retraining required.
Production requires infrastructure before model selection — the evaluation pipeline, the Strands Agent boundary, the observability stack, and the data foundation must be in place before you pick a model. This is the discipline that separates production systems from expensive demos.
Written by AJ · AWS AI Hero · Co-organizer, AWS User Group Bengaluru · Host, DataOps Labs Podcast
Architecture validated in production at a large regulated enterprise.
Series navigation:
Part 1 (this post): The Problem, the Architecture Insight, the Value Stream
Part 2: Full AWS Architecture · Bedrock · AgentCore · S3 Tables · Production Playbook