You've tuned your embedding model. You've benchmarked retrieval algorithms. You've swapped LLMs. And your RAG system still gets the wrong answer.
Here's what nobody tells you upfront: the bottleneck is almost never the retrieval step. It's what happened to your PDFs before the text ever hit the vector store.
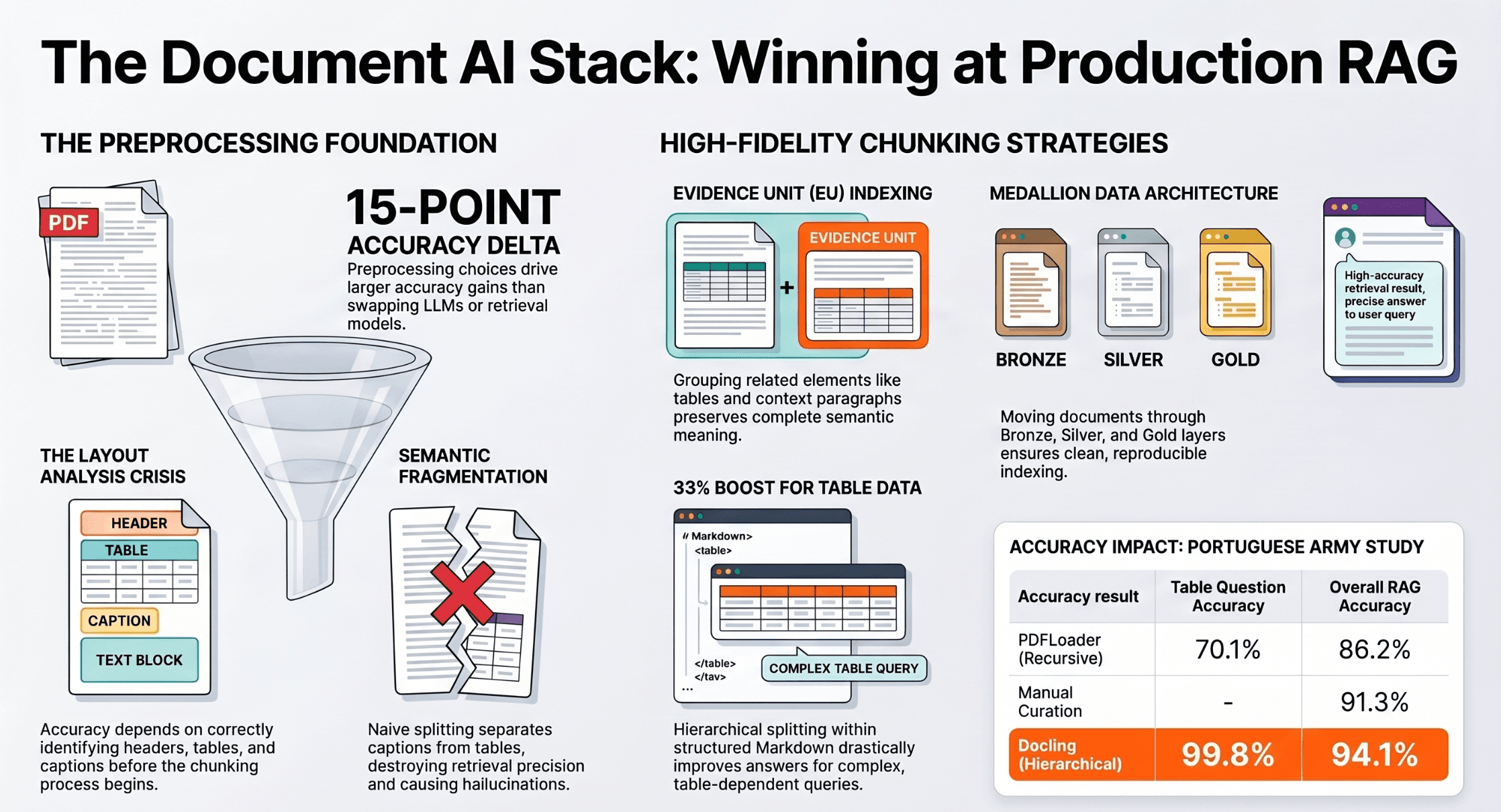
Over the past year, a cluster of research papers has quietly redefined what "good document preprocessing" means for RAG. Not in the abstract — in measurable, statistically significant accuracy deltas. We're talking about a 15 percentage-point accuracy swing across configurations where the only variable was how documents were parsed and chunked. The LLM was identical. The embedding model was identical. The retrieval K was identical.
This post synthesizes six papers spanning layout detection model training, multimodal RAG pipelines, invoice extraction benchmarks, ontology-grounded chunking, PDF-to-Markdown conversion evaluation, and domain-specific educational RAG. Together they reveal a coherent story about what the modern document AI stack actually requires — and where most implementations fall dangerously short.
What We Are Building
The goal is a production-grade document intelligence pipeline that can:
Ingest heterogeneous document formats (PDF, DOCX, PPTX, scanned images, audio, video) Extract layout structure with high fidelity — not just text, but tables, figures, captions, equations, headers Chunk documents into semantically complete retrieval units rather than token-count fragments Index with hybrid dense-sparse embeddings Serve RAG queries with provably higher recall and lower hallucination rates than naive pipelines
The architecture spans three distinct layers that most teams treat independently but must be designed together.

Each layer has failure modes that cascade downstream. A layout model that misidentifies a table as a picture sends broken data into the chunker. A chunker that splits captions from their tables destroys retrieval precision. A naive text splitter that ignores document hierarchy makes table-dependent questions nearly unanswerable.
Let's walk through each layer in depth.
Layer 1: Layout Analysis — The Foundation Everything Depends On
What Problem It Solves
Before you can chunk a document intelligently, you need to know what's in it. Not just the raw text stream — the semantic structure. Is this block a table? A figure caption? A section header? A footnote? A formula?
The Document Layout Analysis (DLA) task identifies and classifies document elements with bounding boxes across a predefined taxonomy. Every downstream decision depends on the accuracy of this step.
How Modern Layout Models Work
IBM Research's Docling project recently published a technical report detailing the development of their new layout model family. The approach is instructive because it reveals decisions that matter at every stage.
Architecture choice: The team evaluated RT-DETRv1, RT-DETRv2 (ResNet-50 and ResNet-101 backbones), and DFINE (HGNet-V2 backbone, three sizes). They exclusively chose Transformer-based detectors and excluded the YOLO family due to licensing constraints — a real-world constraint that matters for enterprise deployments.
The resulting model family:

The headline result: heron-101 achieves 78% mAP with 28ms inference on a single A100 GPU — a 23.9% improvement over Docling's prior baseline.
The Dataset Engineering Problem
Training these models required solving a dataset problem that most engineers never think about. The DocLayNet dataset covers only 11 of the 17 canonical layout classes. It omits "Document Index", "Code", "Checkbox-Selected", "Checkbox-Unselected", "Form", and "Key-Value Region" — what the paper calls "delta classes."
The consequence is subtle but severe: pages that do contain delta-class elements but lack annotations for them become incorrectly supervised training samples. A "Form" annotated as a "Table" during training teaches the model the wrong thing.
The fix was a filtering pipeline: train a preliminary detector on a small curated set covering all 17 classes, then use it to scan DocLayNet at low confidence thresholds (0.3) to flag pages likely containing delta elements, and exclude those pages. This produced a "canonical DocLayNet" with 22,101 training samples that resulted in measurably better mAP — 7.5% to 8.4% higher than the uncleaned dataset.
Lesson: Your training data quality matters more than your architecture choice. The delta-class filtering approach is replicable for any domain-specific taxonomy you need to support.
The mAP Metric Problem
Here's an uncomfortable finding from the paper: higher mAP scores don't always mean better documents.
The team noticed that raw predictions without post-processing score highest on mAP but look terrible visually — many overlapping bounding boxes, fragmented elements. Post-processing (merging fragments, removing overlaps, adjusting boxes to PDF cell boundaries) produces cleaner results that are far more useful for downstream tasks, but scores lower on mAP because the metric penalizes box adjustments.
This is a significant finding for anyone building evaluation frameworks. mAP was designed for general object detection. For document conversion, you need task-specific metrics that measure what actually matters: does the downstream system produce correct answers?

Layer 2: The Chunking Crisis Nobody Diagnoses
Why Your Chunks Are Broken
Consider this scenario: a user asks "What was the total revenue in Q3?" Your vector store has indexed the following elements as separate chunks:
Chunk A: "Table 3: Revenue by Segment (Unit: million USD)" Chunk B: A table with actual revenue numbers Chunk C: "As shown in Table 3, total revenue grew 12% year-over-year"
The retriever finds Chunk A (caption similarity = 1.00) and Chunk C (mentions Q3 context) but ranks Chunk B lower because raw table data has low text similarity to a natural language query. The LLM receives the caption and the analysis paragraph but not the actual numbers. Hallucination ensues.
This is semantic fragmentation — the dominant failure mode in production RAG that most teams don't isolate because they're focused on the wrong variables.
Evidence Units: A Principled Solution
Research from KT (Korea Telecom) introduces Evidence Units (EUs): parser-independent, semantically complete document chunks that group visual assets with their contextual text through a three-stage pipeline.
The core insight: a table's caption, unit label, the table body itself, and the explanatory paragraph that interprets it are a single evidence unit. They should be indexed together and retrieved together. Right now, almost every chunking system treats them as independent fragments.

How EU Construction Works
The pipeline has three stages:
Stage 1: Ontology-Grounded Role Normalization
Different parsers use different label vocabularies. Docling calls section headers "heading". MinerU calls them "title". The EU pipeline normalizes these to canonical roles via a DoCO-extended ontology (DSO) with cascaded priority:
# Priority 1: Text pattern matching (parser-independent)
"(Unit: million)" → unit_label # regex: ^\(\s*[Uu]nit\s*:
"[R&D Projects]" → topic_title # regex: ^\[.+\]$
# Priority 2: Parser TYPE_MAP from ontology altLabels
Docling "heading" → section_header
MinerU "title" → section_header
Parser A "SectionHeader" → section_header
# Priority 3: Embedding similarity fallback (unknown parsers)
cosine_sim(raw_label, canon_role) >= 0.80 → assign canon_role
This makes the pipeline zero-shot compatible with any new parser — you just add altLabel entries to the ontology.
Stage 2: Three-Phase EU Contruction
Phase A — Visual-Core Formation: Tables, charts, and pictures become EU "seeds." Only structural roles (section headers, unit labels) attach via spatial proximity:
d_spatial(v, n) = v_gap(v, n) + 0.3 · x_diff(v, n) < 0.30
Adjacent visual EUs (Y-gap < 0.22) within the same section merge into a stat_panel.
Adjacent visual EUs (Y-gap < 0.22) within the same section merge into a stat_panel. This handles Docling's behavior of splitting a single table into three row-level bounding boxes — they merge in Phase A because their Y-gap is 0.00.
Phase B — Global Semantic Allocation: Support paragraphs attach via a full similarity matrix, not local proximity:
# For all unassigned paragraphs × all existing EUs
M[i][j] = max(cosine_sim(para_i_embedding, member_k_embedding)
for member_k in EU_j)
# Assign para to best-matching EU (if similarity >= 0.40)
para_i → argmax_j M[i][j] if max_j M[i][j] >= τ (τ = 0.40)
# Unmatched paragraphs preserved as independent EUs
# (no information loss)
The global matrix is the critical difference from prior work which used local neighborhood matching. Local matching uses a higher threshold (0.70) and discards unmatched elements. Global allocation uses a lower threshold (0.40) because context is richer, and preserves everything.
Phase C — Residual Consolidation: Remaining unassigned elements consolidate by section boundaries, proximity to visual EUs, or spatial contiguity.
Stage 3: Graph-Based Validation
Decision rules are stored in Neo4j as graph-resident specifications rather than hardcoded thresholds. This enables runtime rule modification without code deployment. Two invariants are enforced:
I1 (Anchoring): A visual EU must contain ≥1 anchor element (section header, unit label, or topic title). Violations trigger a search for nearby anchors; if none found, element demotes to plain text.
I2 (Type Consistency): A stat_panel (merged table + chart) must represent the same data: |table_values ∩ chart_values| / |chart_values| >= 0.60. Violations split the panel.
One of the most elegant properties of the EU approach is spatial footprint convergence: even though different parsers decompose the same page region differently, the bounding box of the complete EU converges to the same document region.
For a single table region, the parsers produced these bounding boxes:
Parser A (HTML-aware): [y:0.27–0.57] — single bbox
Docling: Three row-level bboxes: [0.27–0.33], [0.33–0.51], [0.51–0.57]
PaddleOCR-VL: [y:0.25–0.59] with ±0.02 VLM error
After EU construction, all parsers converge to EU footprint [y:0.07–0.82] with IoU ≥ 0.88. The non-visual members (section header, caption, unit label, paragraphs) are recognized consistently across parsers and dominate the final span.
Layer 3: The Preprocessing-RAG Accuracy Link (Now With Data)

The Hierarchy-Aware Chunking Mechanism
The hierarchical recursive splitter works differently from standard character-based splitting:
Standard Recursive:
[---1000 chars---][---1000 chars---][---1000 chars---]
Ignores: section boundaries, table structure, headers
Markdown Recursive:
[# Section A][# Section B content][# Section C]
Respects: markdown headers and list structure
Hierarchical Recursive (Docling-specific):
[breadcrumb: "Doc > Chapter 3 > 3.2 Revenue Tables"] + [table content]
Each chunk: path-from-root + bounded-by-section-markers + content
Each chunk is prepended with the full breadcrumb path through the document hierarchy. When a retriever scores chunks for relevance, the LLM sees not just the content but where in the document it lives. This enables Chain-of-Thought filtering of irrelevant sections.
This strategy requires well-structured Markdown — which is why the conversion framework choice matters. Only Docling (and hand-crafted outputs) reliably produce the heading hierarchy that hierarchical splitting depends on.
The GraphRAG Negative Result
The study also explored GraphRAG: building a Neo4j knowledge graph with ~20,000 entity nodes and ~26,000 relationships from LLMGraphTransformer. The expectation was that structured entity-relationship retrieval would outperform pure vector search.
It didn't. GraphRAG scored 82% versus basic RAG's 94.1%. Entity deduplication made it slightly worse (81%).
Post-mortem analysis revealed three failure modes:
Graph sparsity: With 20,000+ entities but low average degree, community detection algorithms (Leiden) find no meaningful communities. The graph has complexity without knowledge density.
Generic extraction: No domain ontology guided entity extraction. The graph mixed semantically distinct concepts that shared surface similarity above the 85% deduplication threshold.
High construction cost: 10+ hours on a DGX Spark workstation for a 36-document corpus. Iterative refinement was effectively impossible.
The lesson isn't that GraphRAG can't work. It's that naive LLM-extracted graphs without ontology design don't compete with a well-configured vector pipeline. The Evidence Units paper is instructive here: its graph layer (Neo4j for decision rules) is a structural graph of document layout elements, not a content graph — and it works precisely because it models a narrow, well-defined domain.

Implementation Walkthrough
Phase 1: Document Ingestion at Scale
For production deployments, single-node Docling is a bottleneck. MMORE (Massive Multimodal Open RAG & Extraction) demonstrates the distributed architecture that's needed.
MMORE's architecture separates concerns into three commands:
# Stage 1: Distributed processing (Dask-based, Kubernetes-ready)
run_process --config config.yaml --input /data/raw --output /data/processed
# Stage 2: Index building (hybrid dense-sparse)
run_indexer --processed /data/processed --vector-db chromadb
# Stage 3: RAG serving
run_rag --index /data/index --model claude-3-5-sonnet

Phase 2: Implementing the Medallion Architecture

For Docling specifically, this configuration achieves 94.1% RAG accuracy — surpassing manually curated Markdown (91.3%):
from docling.document_converter import DocumentConverter
from docling.chunking import HierarchicalChunker
# Configure Docling with VLM image descriptions
converter = DocumentConverter(
artifacts_path="./artifacts",
pdf_backend="pypdfium2",
table_structure_options={"do_cell_matching": True},
ocr_options={"lang": ["en", "de", "pt"]},
# Enable image description via external VLM
image_description_options={
"enabled": True,
"model": "gpt-4o-vision",
}
)
# Convert
doc = converter.convert("document.pdf").document
# Hierarchical chunking with breadcrumb metadata
chunker = HierarchicalChunker(
tokenizer="gpt-3.5-turbo", # for token counting
max_tokens=300,
include_xml_tags=False,
merge_peers=True,
)
chunks = list(chunker.chunk(doc))
# Each chunk contains: text + heading_path (breadcrumb) + metadata
for chunk in chunks:
text = chunk.text
breadcrumb = " > ".join(chunk.meta.headings) if chunk.meta.headings else ""
# Prepend breadcrumb to the chunk text for retrieval
indexed_text = f"[{breadcrumb}]\n\n{text}" if breadcrumb else text
collection.add(
documents=[indexed_text],
metadatas=[{
"source": chunk.meta.origin.filename,
"breadcrumb": breadcrumb,
"page": chunk.meta.origin.page_no,
}],
ids=[f"{doc_id}_{i}"]
)
The ARIA educational RAG paper demonstrates what happens when documents contain non-textual content that carries critical information — engineering diagrams, mathematical formulas, structural schematics.
Standard Docling on a torsion analysis slide deck extracts 3,924 characters with formula placeholders (). The full ARIA pipeline extracts 20,760 characters — a 65.2% increase — by running three parallel extractors:
# Three-pathway extraction for technical documents
def extract_technical_pdf(pdf_path: str) -> dict:
# Pathway 1: Docling for structure + tables + text
doc = docling_converter.convert(pdf_path).document
structured_text = doc.export_to_text()
# Pathway 2: Nougat for mathematical formulas → LaTeX
images = pdf_to_images(pdf_path)
formula_latex = nougat_model.extract_formulas(images)
# Pathway 3: GPT-4 Vision for diagrams + schematics
diagram_descriptions = []
for img in images:
desc = gpt4v_client.analyze(
image=img,
prompt="Describe all engineering diagrams, free body diagrams, "
"and structural schematics. Include dimensional labels, "
"force vectors, and geometric relationships."
)
diagram_descriptions.append(desc)
# Merge into unified representation
return {
"structured_text": structured_text,
"formulas": formula_latex,
"diagrams": diagram_descriptions,
"merged": merge_modalities(structured_text, formula_latex, diagram_descriptions)
}

For engineering and scientific documents, this matters enormously. A formula expressed in LaTeX is computationally manipulable. A formula described in natural language ("the shear stress equals the torque times the radius divided by the polar moment of inertia") cannot be validated programmatically.

Challenges Encountered

Lesson Learnt

Reference on Portuguese military document - https://arxiv.org/abs/2604.04948
Production Consideration
Security
Document access control: The Medallion Architecture's layered approach (Bronze/Silver/Gold) provides natural points for access control enforcement. Raw documents in Bronze can have strict ACLs; Gold layer outputs can be filtered by organizational role before indexing.
PII in extracted text: OCR and layout models extract everything, including redacted content that wasn't correctly redacted in the source PDF. Implement PII detection at the Silver layer before Gold layer indexing.
Model licensing: The Docling paper's explicit exclusion of YOLO models due to licensing constraints is a reminder to audit your model licenses before production deployment. RT-DETRv2 and DFINE are available under permissive licenses.
Governance
Extraction audit trail: Maintain a mapping from every indexed chunk to its source document, page, and bounding box. The EU framework's EU metadata structure (document ID, page, spatial footprint) provides this. Citation traceability is non-negotiable for regulated domains.
Configuration versioning: Because preprocessing choices so dramatically affect accuracy, version your pipeline configurations alongside your model versions. A change from Markdown Recursive to Hierarchical splitting is a breaking change for your retrieval behavior.
Observability
Design observability from day one:
# Key metrics to instrument
extraction_layer:
- character_extraction_rate_by_doc_type
- ocr_character_error_rate
- layout_class_distribution
- formula_extraction_success_rate
- processing_time_per_page
chunking_layer:
- chunk_size_distribution
- eu_type_distribution (table_panel / chart_panel / section_text)
- phase_assignment_rates (A / B / C)
- invariant_violation_rate (I1 / I2)
- semantic_similarity_distribution
retrieval_layer:
- recall_at_1_3_5
- min_k_distribution
- avg_lcs_by_evidence_type
- table_question_accuracy
- hierarchy_dependent_accuracy
If you only instrument one thing, instrument Recall@1 by question type. It will tell you exactly where your pipeline is failing.
Cost Optimization
Tiered processing: Route digital PDFs to fast-mode processing (no OCR) and scanned documents to full OCR. MMORE's fast mode achieves 2-3× speedup over default mode on digital documents with negligible accuracy loss.
VLM image descriptions selectively: The +2.9 pp accuracy gain from image descriptions is significant, but VLM API calls are expensive at scale. Apply image description only to documents with diagram-dependent questions, or only to image-heavy document categories.
Embedding model selection: e5-large-v2 achieves equivalent Recall@5 to text-embedding-3-large at 6.6× lower latency and 2.5× lower storage. For large document corpora, this difference is material.
Batch processing for layout models: The Docling paper shows that small layout models struggle to saturate an A100 GPU at small batch sizes. Use batch sizes ≥100 and 32 CPU threads for data loading to approach hardware limits.
Scaling
Horizontal document processing: MMORE's Dask-based architecture achieves near-linear scaling from 1 to 4 nodes. Beyond 4 nodes, coordination overhead appears. For very large corpora (millions of pages), consider partitioning by document category.
EU construction scales with document complexity, not size: Phase B's global similarity matrix is O(paragraphs × EUs) per page, not O(document size). Long documents with simple structure (mostly text) scale well. Dense technical documents with many figures scale less well.
Index size with EU chunks: EU chunks are 4.7× larger than element-level chunks on average (2,931 vs. 623 characters). Your index will be larger, but retrieval quality improves enough that you can often reduce K from 200 to 50, partially offsetting the storage increase.
Reliability
Parser failure handling: Docling fails on ~1% of documents in production (13/1,342 in the OmniDocBench evaluation). MinerU fails on ~0.07%. Build fallback handling: if primary parser fails, retry with secondary, then fall back to PyPDF2 with explicit quality flagging.
OCR confidence thresholds: The delta-class filtering in the Docling training data is a template for production quality gating. If an extracted element's confidence is below threshold, flag it for human review rather than silently indexing low-quality content.
Future Enhancements
Cross-page Evidence Units: The current EU framework is single-page. Cross-page figure references and cross-section table references require a second pass using explicit reference parsing ("see Table 3 on page 12") followed by EU linkage.
Adaptive chunking by document type: Legal documents are text-dense and benefit from hierarchical splitting. Brochures are image-heavy and benefit from EU grouping. Mixing a single strategy across document types leaves accuracy on the table.
Self-correcting extraction pipelines: ARIA's confidence-per-field output (from the invoice extraction comparison) suggests a viable pattern: extract, estimate confidence, and route low-confidence fields to human review or a more capable (and expensive) extraction model.
Domain-specific layout ontologies: The 17-class taxonomy in Docling's training is general-purpose. For medical documents (radiology reports, clinical notes), financial documents (balance sheets, footnotes), or legal documents (clauses, definitions, citations), domain-specific class extensions would improve layout accuracy and downstream EU construction.
Multilingual EU construction: The ontology's skos:altLabel mechanism supports parser-independent normalization. Extending this to multilingual parser variants (Chinese OCR labels, Arabic text direction handling) is the natural next step.
Online EU updating: Current EU construction is batch-only. For real-time document ingestion (email, Slack threads, live document editing), incremental EU construction that updates existing EUs when new elements arrive is an open problem.