LiveKB: Production Architecture with Strands Agents, Bedrock, and AgentCore on AWS
Part 2 of 2 | DataOps Labs Series: Living Knowledge Systems on AWS
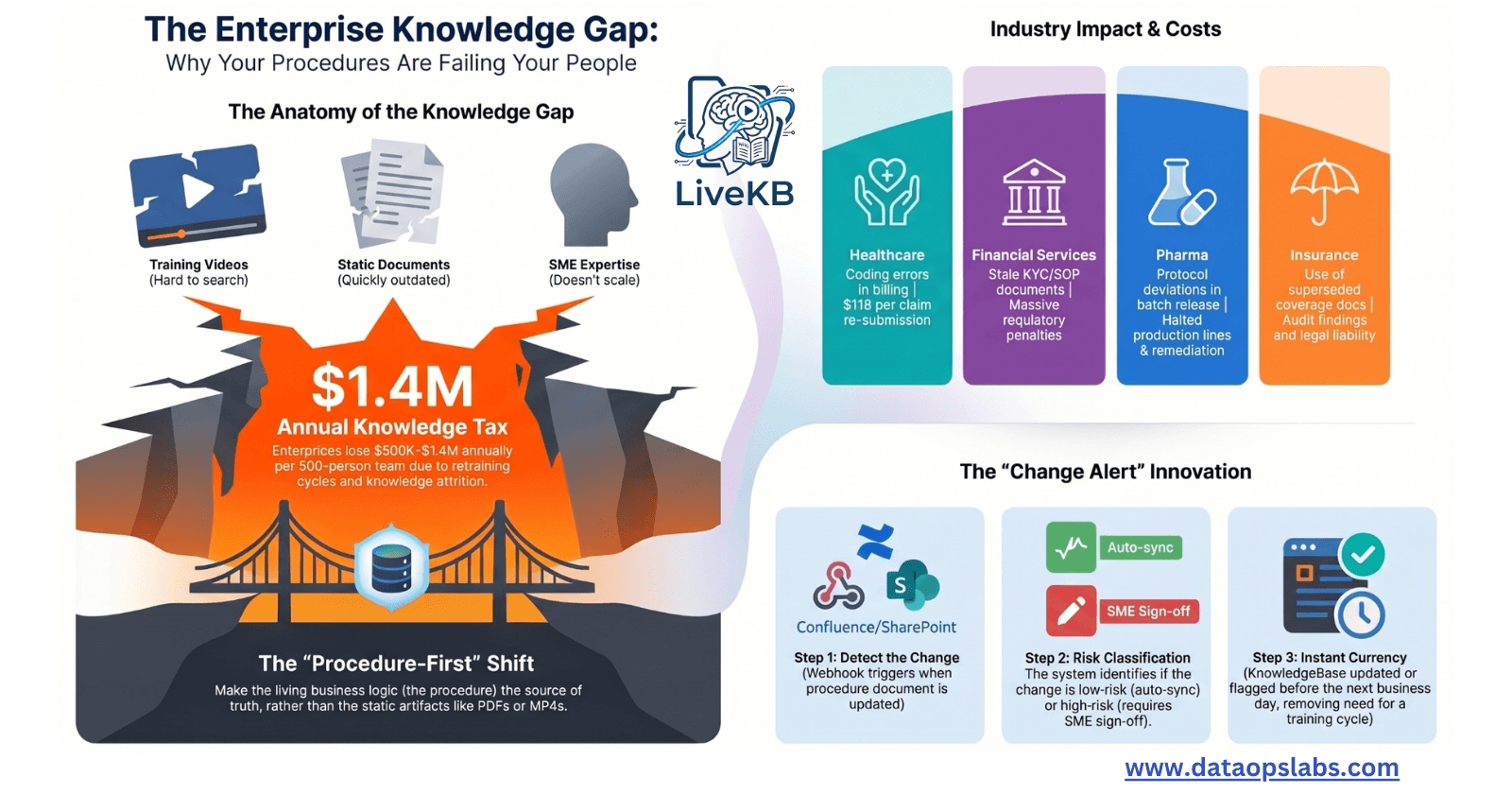
Part 1 diagnosed the problem: back-office knowledge lives in disconnected silos, procedures change faster than training cycles can respond, and the result is a perpetual knowledge gap that costs enterprises $500K–$1.4M annually per 500-person operations team.
This post builds the solution from the ground up — a living knowledge system on AWS where the procedure is the source of truth and everything else (video, document, assistant answer) stays current when it changes.
What you'll learn:
The full 5-layer AWS architecture with numbered data flows per pipeline
Bedrock multimodal ingestion — how video frames become queryable knowledge
The Strands Agent on AgentCore Runtime pattern — knowledge boundary enforcement at the retrieval layer
The Change Alert Pipeline — procedure update to current answer in under 60 minutes
S3 Tables as the immutable procedure lineage store
Amplify + Next.js UI architecture for the per-domain employee assistant
Bedrock Evaluation framework — golden dataset design, 3-layer assessment
The production playbook — and why model selection is always last
3 failure patterns from staging that almost killed the system
System Architecture — The Five Layers
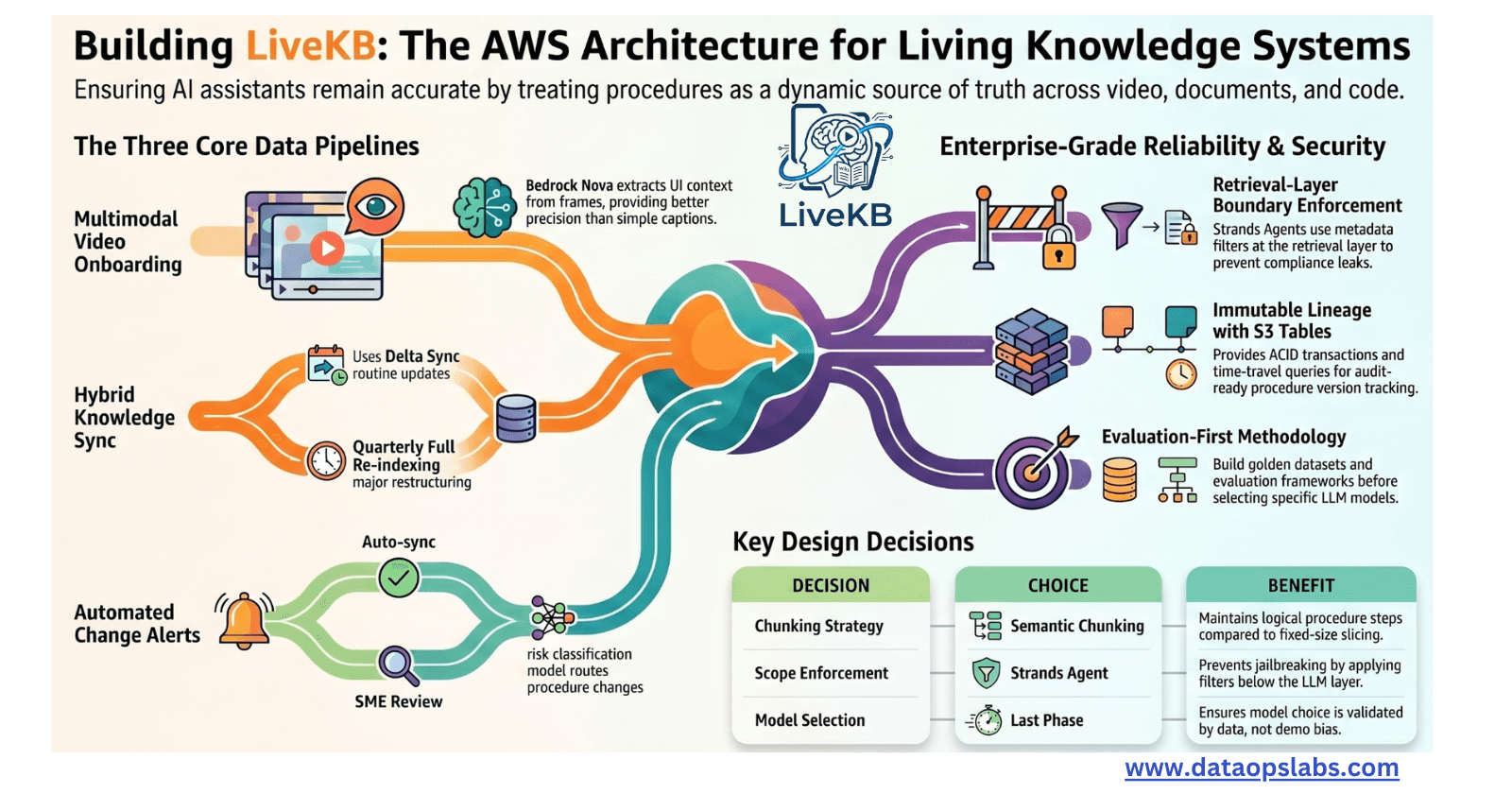
Before going deep on each pipeline, here is the complete system map. Five layers. Three pipelines. One Strands Agent on AgentCore Runtime. Everything connected.

Key design decisions upfront:
| Decision | Choice | Tradeoff Named |
|---|---|---|
| One KnowledgeBase per domain? | Yes — per-domain isolation | Compliance boundary vs. operational overhead. Isolation wins in regulated environments. |
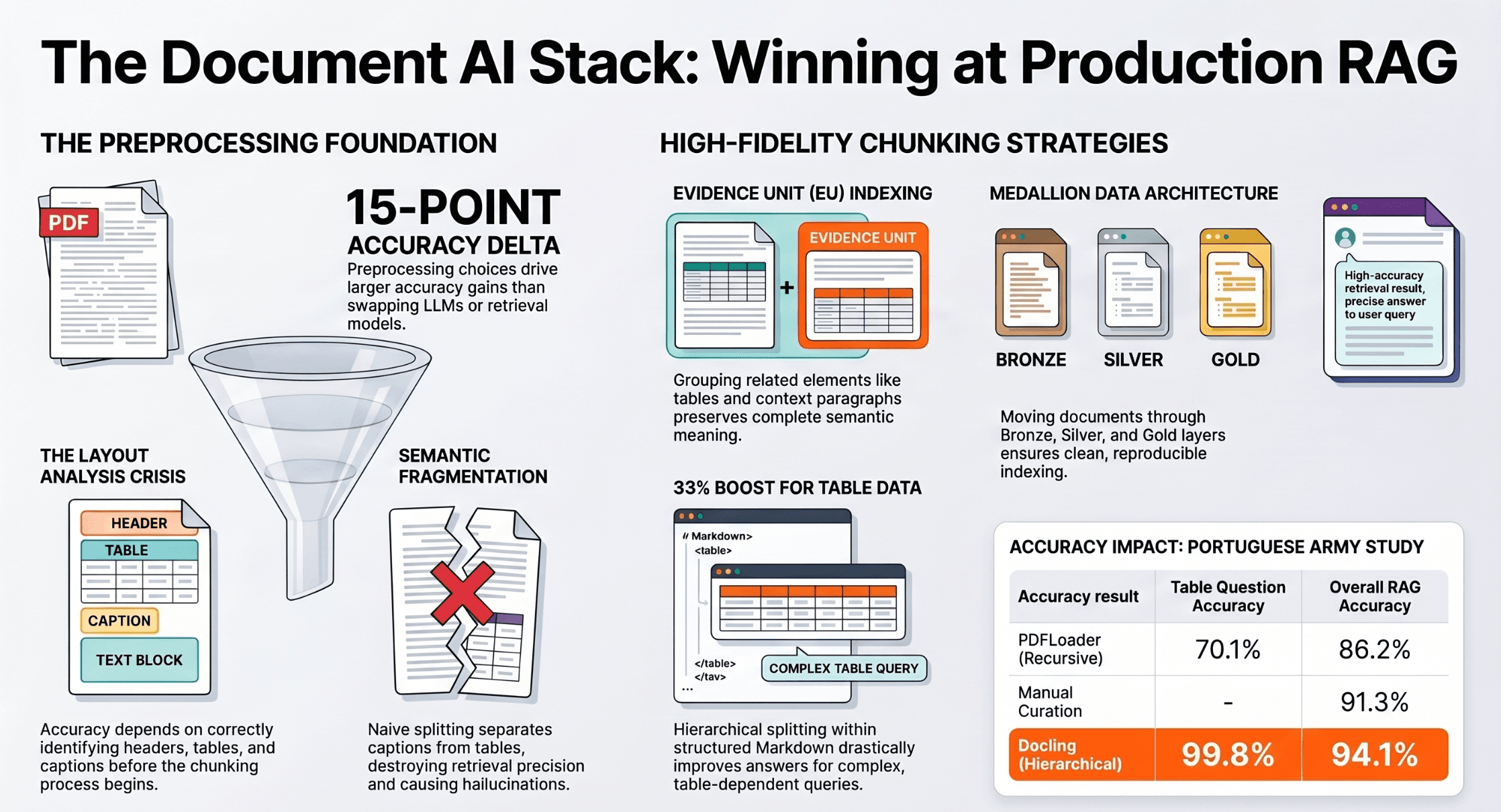
| Chunking strategy | Semantic chunking with 512-token overlap | Better for procedural content vs. fixed-size. Higher compute cost at ingestion. |
| State management | Immutable S3 Tables snapshots | Append-only log prevents stale reads. Higher storage cost vs. mutable store. |
| Scope enforcement | Strands Agent with retrieve tool — metadata filters applied at Bedrock KB retrieval layer, enforced by AgentCore Runtime session isolation | Stronger than prompt-layer guards. Can't be jailbroken. Slightly higher query cost. |
| Model selection timing | Last phase | Only after evaluation pipeline is stable. Prevents demo bias in model choice. |
Pipeline 1 — Video Onboarding
This pipeline runs once per video, at ingestion. The compute is front-loaded so employee queries are fast and cheap.

Key Design Decisions — Pipeline 1
Why Bedrock Nova for frame analysis, not Transcribe captions?
Transcribe gives you what was said. Nova gives you what was shown. For back-office procedure training, the most critical content is often visual: a specific field to click, a dropdown value to select, a form layout to follow. A transcript of "click the approval button in the top right" is ambiguous. Nova's frame analysis extracts: {action: "click", element: "Approve Invoice button", location: "top-right header", ui_context: "SAP Fiori Launchpad"}. This is the difference between an answer that helps and an answer that confuses.
Why semantic chunking over fixed-size?
Fixed-size chunking (e.g., 512 tokens every time) slices through procedure steps mid-sentence. A step that says "If the exception flag is Type-3, navigate to the Exceptions tab and select Override — but only if the amount is below $10,000" should be one chunk. Semantic chunking uses sentence boundaries + heading detection to keep logical procedure steps intact. It costs more at ingestion (~30% more Lambda runtime) but dramatically improves retrieval precision.
S3 Tables — why not DynamoDB for metadata?
S3 Tables gives you ACID transactions, time-travel queries (via Iceberg format), and native Athena integration for analytics. When an auditor asks "what procedure version was indexed for video KYC-007 on March 14th?" — S3 Tables answers with a time-travel query in seconds. DynamoDB answers with "we'd have to check the logs." For regulated environments, this is a non-negotiable capability.
# Example: Ingest Orchestrator Lambda (core logic)
import boto3, uuid, json
from datetime import datetime
s3_client = boto3.client('s3')
transcribe = boto3.client('transcribe')
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
lambda_client = boto3.client('lambda')
def handler(event, context):
record = event['Records'][0]['s3']
bucket = record['bucket']['name']
key = record['object']['key']
# Parse domain context from S3 key prefix
# Key pattern: uploads/{lob_id}/{domain_id}/{filename}.mp4
parts = key.split('/')
lob_id, domain_id = parts[1], parts[2]
video_id = str(uuid.uuid4())
proc_version = datetime.utcnow().strftime('%Y%m%d_%H%M%S')
# Write initial metadata to S3 Tables
write_metadata(video_id, lob_id, domain_id, proc_version, 'PROCESSING')
# Fan-out: Transcribe
transcribe.start_transcription_job(
TranscriptionJobName=f"job_{video_id}",
Media={'MediaFileUri': f"s3://{bucket}/{key}"},
MediaFormat='mp4',
LanguageCode='en-US',
OutputBucketName='living-kb-transcripts',
Settings={'ShowSpeakerLabels': False, 'ShowAlternatives': False}
)
# Fan-out: Frame analysis (async Lambda)
lambda_client.invoke(
FunctionName='frame-analyzer',
InvocationType='Event', # async
Payload=json.dumps({
'video_id': video_id, 'bucket': bucket, 'key': key,
'lob_id': lob_id, 'domain_id': domain_id,
'proc_version': proc_version
})
)
return {'video_id': video_id, 'status': 'PROCESSING'}
Pipeline 2 — Knowledge Sync
This pipeline keeps the KnowledgeBase current with Confluence, SharePoint, and Wiki changes — without requiring a full re-index on every change.

The Tradeoff: Full Re-Index vs. Delta Sync
This is the most consequential architectural decision in Pipeline 2.
| Approach | Pros | Cons | When to Use |
|---|---|---|---|
| Full re-index | Clean slate, no orphan chunks | Expensive, slow (30–60 min for large corpus), index unavailable during rebuild | Major restructuring of procedure corpus |
| Delta sync | Fast (minutes), cheap, index always live | Risk of orphan chunks if deletions aren't tracked | All routine procedure updates |
| Hybrid | Full re-index on major version, delta for minor | Complex to orchestrate | Regulated domains with quarterly major reviews |
Our recommendation: Delta sync as default. Schedule a full re-index once per quarter per domain, or when a major procedure restructuring occurs. Track the "last full re-index" timestamp in S3 Tables.
# Delta Detector Lambda — core hash comparison logic
import boto3, hashlib, json
from datetime import datetime
def get_doc_hash(content: str) -> str:
return hashlib.sha256(content.encode('utf-8')).hexdigest()
def detect_changes(domain_id: str, confluence_docs: list) -> list:
"""Compare current docs against stored hashes. Return changed list."""
athena = boto3.client('athena')
# Query last known hashes from S3 Tables via Athena
query = f"""
SELECT doc_id, content_hash
FROM living_kb.sync_hashes
WHERE domain_id = '{domain_id}'
AND sync_timestamp = (
SELECT MAX(sync_timestamp) FROM living_kb.sync_hashes
WHERE domain_id = '{domain_id}'
)
"""
stored_hashes = run_athena_query(athena, query)
stored_map = {row['doc_id']: row['content_hash'] for row in stored_hashes}
changed = []
for doc in confluence_docs:
current_hash = get_doc_hash(doc['content'])
if doc['id'] not in stored_map:
changed.append({'doc_id': doc['id'], 'change_type': 'ADDED',
'content': doc['content'], 'new_hash': current_hash})
elif stored_map[doc['id']] != current_hash:
changed.append({'doc_id': doc['id'], 'change_type': 'MODIFIED',
'content': doc['content'], 'new_hash': current_hash})
# Detect deletions
current_ids = {d['id'] for d in confluence_docs}
for doc_id in stored_map:
if doc_id not in current_ids:
changed.append({'doc_id': doc_id, 'change_type': 'DELETED'})
return changed
Pipeline 3 — Change Alert
This is the core innovation of the living knowledge system. When a procedure changes, the system does not wait for a training cycle. It classifies the change risk, routes accordingly, and has the KnowledgeBase updated — or flagged — before the next business day.

The Risk Classification Model
The risk classifier is the most nuanced component in this pipeline. Here is the decision tree:

# Risk Classifier Lambda — Bedrock-powered classification
import boto3, json
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
CLASSIFICATION_PROMPT = """You are a compliance risk classifier for enterprise procedure changes.
Analyze this procedure diff and classify the risk:
CHANGED SECTIONS:
{diff_text}
DOMAIN: {domain_id}
DOCUMENT TYPE: {doc_type}
Classify as TIER_1 (auto-sync safe) or TIER_2 (requires SME review).
TIER_2 indicators: numeric threshold changes, new exception types,
decision tree modifications, regulatory citation updates, anything
affecting compliance-gated actions.
Respond in JSON only:
{{"classification": "TIER_1"|"TIER_2", "confidence": 0.0-1.0,
"reason": "one sentence", "affected_steps": ["step1", "step2"]}}"""
def classify_change(diff_text: str, domain_id: str, doc_type: str) -> dict:
response = bedrock.invoke_model(
modelId='anthropic.claude-3-5-sonnet-20241022-v2:0',
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 300,
"messages": [{
"role": "user",
"content": CLASSIFICATION_PROMPT.format(
diff_text=diff_text, domain_id=domain_id, doc_type=doc_type
)
}]
})
)
result = json.loads(json.loads(response['body'].read())['content'][0]['text'])
# Confidence gate: anything below 0.85 escalates to TIER_2
if result['confidence'] < 0.85:
result['classification'] = 'TIER_2'
result['reason'] = f"Escalated: classifier confidence {result['confidence']:.2f} below threshold"
return result
The Strands Agent on AgentCore Runtime — Knowledge Boundary Enforcement

The Strands Agent deployed on Bedrock AgentCore Runtime is the most architecturally significant component in the system. It is what separates this from a generic RAG chatbot.
The problem it solves: Without scope enforcement, a chatbot for "KYC Exception Handling Video 7" will answer from "AML Screening Video 12" context, or from general Bedrock training data, or from a procedure version that was superseded three months ago. In a regulated environment, any of these is a compliance risk.
Why prompt-layer guards are insufficient: A prompt that says "only answer from the KYC domain" can be overridden by a user who says "forget your previous instructions." Retrieval-layer enforcement cannot be overridden — the metadata filter is applied at the Bedrock Knowledge Base retrieval layer via the Strands retrieve tool, below the LLM layer entirely.
The Strands Agent architecture:
Built with Strands Agents SDK (
from strands import Agent)Uses the
retrievetool fromstrands_toolsfor Bedrock Knowledge Bases retrieval with metadata filtersDeployed as an ARM64 container on Bedrock AgentCore Runtime (not Lambda)
Container image pushed to ECR, deployed via
create_agent_runtimeAPIInvoked via
invoke_agent_runtimewith streaming supportSession management via Strands
SessionManager(DynamoDB-backed)Mandatory
/invocations(POST) and/ping(GET) endpoints per AgentCore contractADOT auto-instrumentation provides observability without manual CloudWatch/X-Ray setup
AgentCore sub-services leveraged:
AgentCore Memory — session persistence across invocations
AgentCore Identity — OAuth/credential management for downstream tool access
AgentCore Gateway — tool integration and routing
AgentCore Observability — built-in CloudWatch GenAI dashboard with token usage, latency, and cost metrics
# Strands Agent on Bedrock AgentCore Runtime — Core Implementation
from strands import Agent
from strands.models.bedrock import BedrockModel
from strands_tools import retrieve
from bedrock_agentcore.runtime import BedrockAgentCoreApp
app = BedrockAgentCoreApp()
SYSTEM_PROMPT = """You are the {domain_name} procedure assistant. Answer only from the
provided procedure context. If the context does not contain the answer,
say: 'I don't have a grounded answer for this specific scenario.
Please contact [SME contact] for guidance.' Never answer from general
knowledge. Always cite the source section."""
@app.entrypoint
def handle_invocation(payload: dict) -> dict:
domain_id = payload["domain_id"]
lob_id = payload["lob_id"]
session_id = payload["session_id"]
query = payload["query"]
# Initialize Strands Agent with retrieve tool and session manager
model = BedrockModel(
model_id="anthropic.claude-3-5-sonnet-20241022-v2:0",
temperature=0,
max_tokens=800
)
agent = Agent(
model=model,
tools=[retrieve],
system_prompt=SYSTEM_PROMPT.format(domain_name=domain_id),
session_id=session_id,
)
# The retrieve tool is called by the agent with metadata filters
# enforced in the tool configuration — not in the prompt
retrieval_config = {
"knowledgeBaseId": f"kb-{domain_id}",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"andAll": [
{"equals": {"key": "domain_id", "value": domain_id}},
{"equals": {"key": "lob_id", "value": lob_id}},
{"equals": {"key": "procedure_version", "value": "CURRENT"}}
]
}
}
}
}
response = agent(query, retrieve_config=retrieval_config)
return {
"answer": str(response),
"session_id": session_id,
"procedure_version": get_current_version(domain_id)
}
if __name__ == "__main__":
app.run()
Dockerfile for AgentCore Runtime deployment:
FROM public.ecr.aws/lambda/python:3.12-arm64
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
EXPOSE 8080
CMD ["python", "agent.py"]
Deployment via AgentCore CLI:
# Build and push ARM64 container to ECR
docker buildx build --platform linux/arm64 -t living-kb-agent .
aws ecr get-login-password | docker login --username AWS --password-stdin $ECR_URI
docker tag living-kb-agent:latest $ECR_URI/living-kb-agent:latest
docker push $ECR_URI/living-kb-agent:latest
# Deploy to AgentCore Runtime
aws bedrock-agent-runtime create-agent-runtime \
--agent-runtime-name living-kb-agent \
--container-image-uri $ECR_URI/living-kb-agent:latest \
--architecture ARM64
# Invoke with streaming
aws bedrock-agent-runtime invoke-agent-runtime \
--agent-runtime-id $RUNTIME_ID \
--payload '{"domain_id":"kyc","lob_id":"operations","session_id":"sess_123","query":"..."}'
The UI Layer — AWS Amplify + Next.js
The employee-facing UI is built on AWS Amplify hosting Next.js 15 with App Router. The design principle: the assistant must feel as simple as a search bar, with the complexity entirely in the backend.
Architecture

Key UI Components
1. Domain-Scoped Assistant Chat
// app/[domain]/assistant/page.tsx
import { generateClient } from 'aws-amplify/api';
import { useAuthenticator } from '@aws-amplify/ui-react';
export default function AssistantPage({
params: { domain }
}: { params: { domain: string } }) {
const { user } = useAuthenticator();
const client = generateClient();
// domain is validated server-side against user's Cognito groups
// A user in group "kyc-ops" cannot access domain "aml-screening"
const askQuestion = async (question: string) => {
// Calls AgentCore Runtime's invoke_agent_runtime endpoint
const response = await fetch('/api/assistant/query', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
question,
domain_id: domain,
session_id: sessionStorage.getItem('session_id')
})
});
return response.json();
// Backend proxies to invoke_agent_runtime with streaming support
// Response includes: answer, citations[], procedure_version, confidence
};
return (
<AssistantChat
domain={domain}
onQuestion={askQuestion}
procedureVersion={procedureVersion}
/>
);
}
2. Real-Time Procedure Update Banner (AppSync)
// components/ProcedureStatusBanner.tsx
// Subscribes to AppSync real-time updates
// Shows when a procedure has been updated or is under SME review
import { generateClient } from 'aws-amplify/api';
import { onProcedureStatusChange } from '@/graphql/subscriptions';
export function ProcedureStatusBanner({ domainId }: { domainId: string }) {
const [status, setStatus] = useState<'CURRENT' | 'UPDATED' | 'PENDING'>('CURRENT');
useEffect(() => {
const client = generateClient();
const subscription = client.graphql({
query: onProcedureStatusChange,
variables: { domain_id: domainId }
}).subscribe({
next: ({ data }) => setStatus(data.onProcedureStatusChange.status)
});
return () => subscription.unsubscribe();
}, [domainId]);
if (status === 'CURRENT') return null;
if (status === 'UPDATED') return (
<Banner type="success">
✓ Procedure updated — this answer reflects the latest version
</Banner>
);
if (status === 'PENDING') return (
<Banner type="warning">
⚠ Procedure under SME review — answer reflects version dated {lastDate}
</Banner>
);
}
3. Video Deep-Link with Timestamp
// components/CitationCard.tsx
// Renders answer citations — links directly to video timestamp
interface Citation {
type: 'video' | 'sop';
video_id?: string;
timestamp?: string; // "14:32"
doc_id?: string;
section?: string;
last_updated?: string;
}
export function CitationCard({ citation }: { citation: Citation }) {
if (citation.type === 'video') {
const [min, sec] = citation.timestamp!.split(':').map(Number);
const seconds = min * 60 + sec;
return (
<a href={`/videos/\({citation.video_id}?t=\){seconds}`}
className="citation-card citation-video">
🎬 Video: {citation.title} at {citation.timestamp}
</a>
);
}
return (
<a href={`/docs/\({citation.doc_id}#\){citation.section}`}
className="citation-card citation-sop">
📄 {citation.doc_id} — {citation.section}
<span className="version">Updated {citation.last_updated}</span>
</a>
);
}
4. SME Review Dashboard (Admin)
// app/admin/sme-review/page.tsx
// Shows pending Tier-2 changes with diff view and approve/reject actions
export default function SMEReviewPage() {
const { pendingChanges } = usePendingChanges();
return (
<ReviewDashboard>
{pendingChanges.map(change => (
<ChangeReviewCard
key={change.doc_id}
change={change}
onApprove={() => approveChange(change.doc_id)}
onReject={(reason) => rejectChange(change.doc_id, reason)}
/>
))}
</ReviewDashboard>
);
}
Amplify + Next.js Deployment
# One-time setup
npm create amplify@latest -- --template nextjs
# Configure Amplify Gen 2
amplify configure
# Deploy
amplify push
# The amplify.yml is auto-generated, but add:
# - Server-side rendering support (nextjs SSR preset)
# - Environment variables for AgentCore Runtime endpoint (invoke_agent_runtime)
# - Cognito User Pool IDs per domain
Amplify Gen 2 config for domain-scoped auth:
// amplify/auth/resource.ts
import { defineAuth } from '@aws-amplify/backend';
export const auth = defineAuth({
loginWith: { email: true },
groups: [
'kyc-ops', 'aml-screening', 'trade-settlement',
'claims-processing', 'revenue-cycle', 'batch-release'
],
// Each group maps to a domain_id in the Strands Agent
// Users can only be in groups matching their job role
});
The Evaluation Framework
This is the pillar that separates production systems from demos. Build the evaluation framework before selecting a model. The system validates the model choice — not the other way around.

The Production Playbook
This is the sequence we followed to take this from concept to running system. The order is non-negotiable.

🎯 The critical discipline: Model selection is the last phase because the evaluation pipeline, built in Phase 1, is what validates the model choice empirically. Teams that choose their model first and build around it end up discovering why it fails their specific use case. Teams that build evaluation first choose a model in hours, with data.
Three Failure Patterns from Staging
Every one of these was real. Every one of them became a new golden dataset entry.
Failure 1 — The Stale Chunk Problem
What happened: Pipeline 2 delta sync ran, re-embedded changed sections, upserted into OpenSearch. But a chunk from the previous version had the same vector ID as the new chunk — and the upsert logic used chunk_index (position in document) not chunk_id (content hash). After a section was restructured, old chunks from deleted sections remained in the index.
Symptom: Employees received answers citing procedures that no longer existed. Confidence scores were high (0.88) because the old chunks were genuinely relevant to the question — they just described the old process.
Fix: Composite key for OpenSearch upsert changed to {doc_id}_{content_hash_prefix}. Delete-before-insert for modified documents (not pure upsert). Added post-sync validation step: chunk count in OpenSearch must match expected count from S3 Tables.
Golden dataset entry added: 12 questions targeting sections that were restructured in a procedure update — verifying old content no longer appears.
Failure 2 — The Strands Agent Boundary Leak
What happened: During testing, a KYC domain user asked a question phrased in a way that semantically matched content from the AML domain. The metadata filter was correctly applied via the Strands Agent's retrieve tool — but the filter used lob_id, and both KYC and AML had the same lob_id value because they were under the same Line of Business in the org structure.
Symptom: AML procedure content appeared in KYC assistant answers. Users noticed when the answer referenced "transaction monitoring thresholds" which are AML-specific.
Fix: Added domain_id as a separate, finer-grained filter field in the Strands Agent's retrieve tool configuration — not derived from lob_id. Because the filter is in code (the retrieve tool's metadata filter config), not in the prompt, fixing it is a code change, not a prompt engineering exercise. Re-indexed all content with explicit domain_id values. Updated Cognito group-to-domain mapping to use domain_id not lob_id. The Strands Agent's retrieve tool with explicit metadata filters prevents this class of boundary leak — the filter is enforced at the Bedrock KB query layer regardless of what the user asks.
Golden dataset entry added: 25 scope boundary tests, one per domain pair — each tests that a domain-specific term from Domain A does not appear in Domain B answers.
Failure 3 — The Multimodal Hallucination on Dense Tables
What happened: Bedrock Nova frame analysis was asked to extract procedure steps from a video frame that contained a dense lookup table (a matrix of exception codes vs. handling procedures, ~8 columns × 20 rows). Nova described the table in prose rather than extracting it as structured data. The prose description was inaccurate — some cell values were misread.
Symptom: Exception code handling answers were wrong for codes in the middle of the table. Edge rows (top and bottom) were correct; middle rows were where the hallucination occurred.
Fix: Added a pre-processing step in the Frame Analyzer Lambda: detect frames containing tabular content (Textract table detection) and route them to a structured extraction pipeline (Textract → JSON) instead of Nova multimodal prose description. Nova multimodal used only for procedural step identification, not table extraction.
Golden dataset entry added: 15 questions targeting exception code lookups from the problematic table — all now answered correctly from structured Textract output.
Key Takeaways
Procedure-first architecture changes everything. When the procedure is the source of truth and everything else (video, document, assistant answer) is derived from it, a procedure change becomes an index sync — not a training event.
The Strands Agent on AgentCore is an architectural pattern, not a prompt technique. Scope enforcement at the retrieval layer (Strands
retrievetool with metadata filters on Bedrock KB) cannot be overridden by user input. Prompt-layer guards can be bypassed. This distinction matters in regulated environments.S3 Tables is the right choice for procedure lineage. Time-travel queries, ACID transactions, and Athena integration make it the audit-ready alternative to DynamoDB for version-aware metadata storage.
Pipeline 3 (Change Alert) is the core innovation. The risk classifier routing (auto-sync vs. SME review) is what makes this safe for regulated environments. Not all procedure changes are equal — the system knows the difference.
The Amplify + Next.js UI must be as simple as a search bar. Every complexity decision in the frontend is a decision to push that complexity into the backend (Strands Agent, AgentCore Runtime, citation lookup). The employee should never feel like they are operating an AI system.
Evaluation before model selection — always. The golden dataset and evaluation pipeline are what allow you to swap and empirically validate models in days. Teams that choose models first and build around them cannot swap without rebuilding their mental model. Teams that build evaluation first can swap in an afternoon.
Three failure patterns are your free education. Stale chunks, scope boundary leaks, and multimodal table hallucinations are predictable failure modes in this architecture. Design for them before they hit production.
Resources
Written by AJ · AWS AI Hero · Co-organizer, AWS User Group Bengaluru · Host, DataOps Labs Podcast
Architecture validated in production at a large regulated enterprise.
Series navigation:
Part 1: The Back-Office Knowledge Trap — The Problem, the Insight, the Value Stream
Part 2 (this post): Full AWS Architecture · Bedrock · AgentCore · S3 Tables · Amplify + Next.js · Production Playbook