DeepSeek V3: Overview, Training, and Benchmark Performance

What is DeepSeek V3?
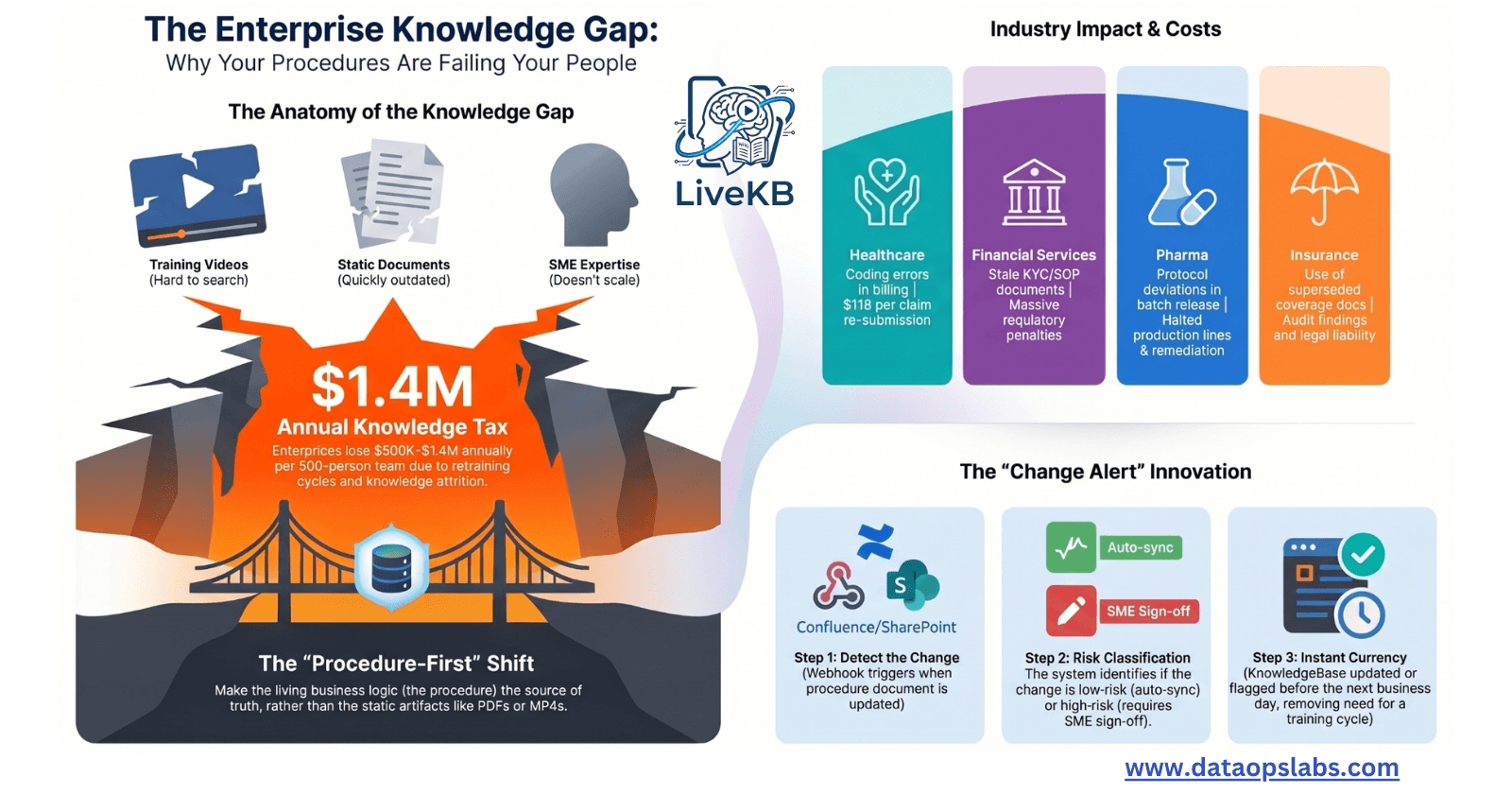
DeepSeek V3 is a state-of-the-art Mixture-of-Experts (MoE) large language model developed to push the boundaries of open-source AI capabilities. It features 671 billion parameters in total, with 37 billion parameters activated per token during inference, achieving an excellent balance between performance and efficiency.
Core Features
Architecture:
Multi-Head Latent Attention (MLA): Reduces memory and computational overhead while maintaining performance comparable to standard attention mechanisms.
DeepSeekMoE:
Allows for fine-grained expert specialization.
Introduces auxiliary-loss-free load balancing, ensuring efficient utilization of resources without degrading performance.
Multi-Token Prediction:
- Trains the model to predict multiple future tokens at once, improving training signal density and inference efficiency.
Training Innovations:
FP8 Mixed Precision Training:
- Employs low-precision FP8 format to reduce memory usage and accelerate computation.
DualPipe Algorithm:
- Optimizes pipeline parallelism by overlapping computation and communication phases, minimizing bottlenecks in large-scale distributed training.
Efficient Cross-Node Communication:
- Custom kernels utilize NVLink and InfiniBand bandwidth for near-zero communication overhead.
Data and Pretraining:
Trained on 14.8 trillion high-quality and diverse tokens.
Extended context lengths from 32K to 128K tokens in two stages.
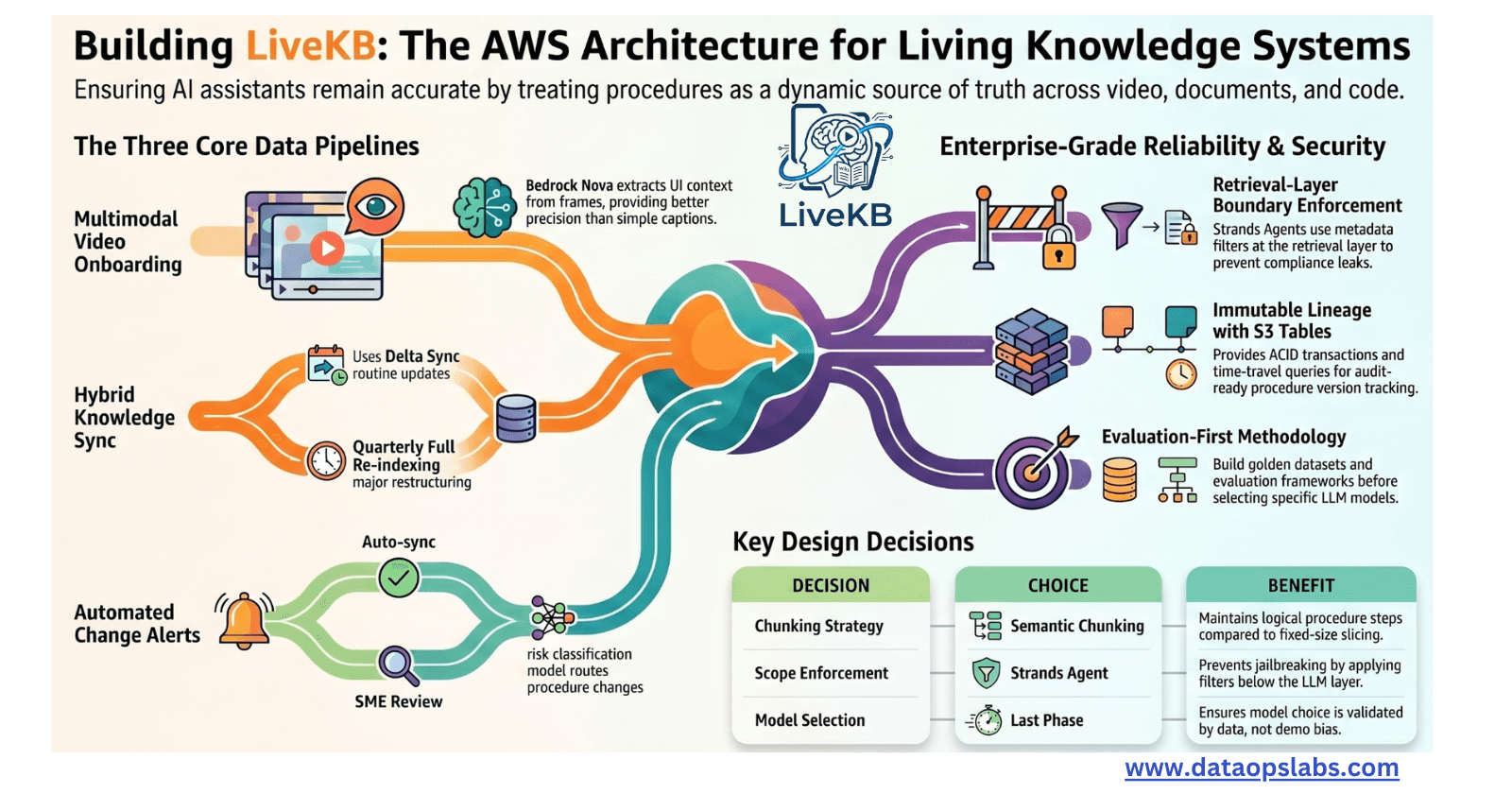
Training Process
Infrastructure:
Trained on a compute cluster with 2048 NVIDIA H800 GPUs.
Each node includes 8 GPUs interconnected via NVLink and NVSwitch, with nodes linked using InfiniBand for high-speed communication.
Cost and Efficiency:
Training required 2.788 million H800 GPU hours (~$5.576 million, assuming $2 per GPU hour).
Breakdown of training stages:
Pretraining: 2.664 million GPU hours.
Context Extension: 119,000 GPU hours.
Post-Training: 5,000 GPU hours.
Optimization Highlights:
Focused on load balancing without relying on auxiliary losses.
Achieved remarkable training stability with no irrecoverable loss spikes or rollbacks.
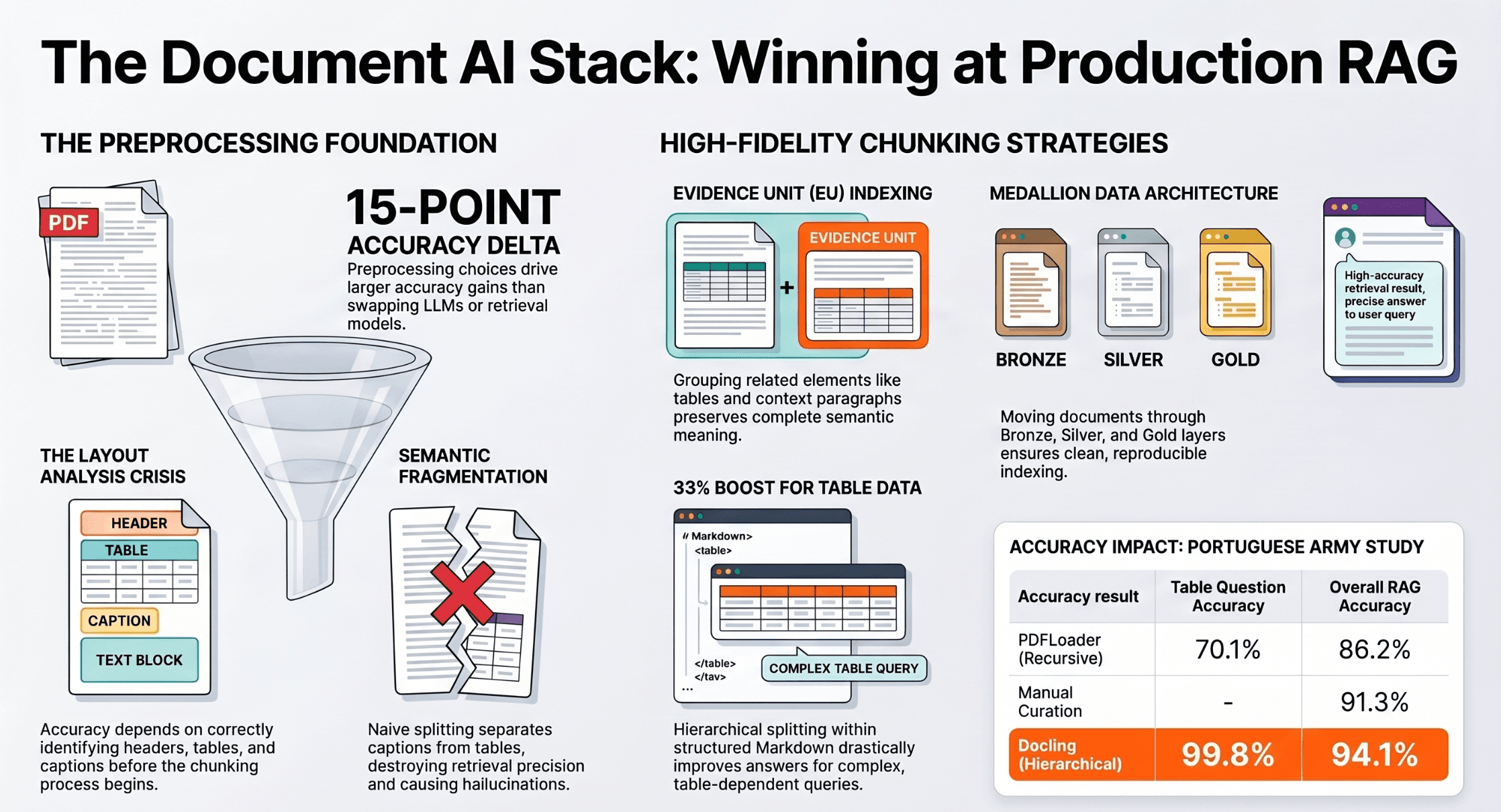
Benchmark Performance
DeepSeek V3 has been evaluated on a wide range of benchmarks, where it demonstrates competitive or superior performance compared to other open-source models.
Knowledge Benchmarks:
MMLU (Massive Multitask Language Understanding):
MMLU-Pro: 75.9% (best among open-source models).
Outperforms LLaMA 3.1-405B and Qwen 2.5-72B on factual and educational tasks.
GPQA Diamond:
- Achieved 59.1%, excelling in factual knowledge.
Math and Reasoning Benchmarks:
MATH-500:
- State-of-the-art performance with 90.2% accuracy.
AIME 2024:
- Scored 39.2% (Pass@1), surpassing many competing models in mathematical reasoning.
Coding and Engineering Benchmarks:
Codeforces (Coding Competition):
- Placed in the 51.6th percentile, demonstrating strong problem-solving skills.
SWE-Bench:
- Verified 42% of submitted solutions, competitive among top models.
Comparison to Other Models:
Matches or exceeds the performance of closed-source models like GPT-4o-0513 and Claude-3.5-Sonnet-1022 in specific tasks.
Outperforms DeepSeek V2.5 and other open-source predecessors by a significant margin.
Why DeepSeek V3 Stands Out
Scalable and Cost-Effective:
Its design prioritizes training efficiency, achieving high performance at lower computational costs.
Advanced communication and memory optimizations allow scaling without prohibitive hardware requirements.
Versatility:
Excels in tasks requiring knowledge, reasoning, and coding abilities.
Supports multi-token prediction, making it well-suited for high-throughput inference scenarios.
Open-Source Leadership:
- Narrowing the gap between open-source and leading proprietary models, DeepSeek V3 serves as a benchmark for collaborative AI development.
Conclusion
DeepSeek V3 combines cutting-edge architecture, efficient training techniques, and exceptional performance across benchmarks, making it a landmark in the realm of large-scale open-source AI. With its superior scalability and cost-effectiveness, DeepSeek V3 is a model of choice for organizations looking to adopt advanced AI solutions without the burden of excessive training costs.