Prompt to Action - Large Action Models-I
Highlights the evolution of AI from language to execution, while hinting at the operational challenges.

Introduction
Large Language Models (LLMs) have demonstrated remarkable prowess in understanding and generating natural language. They serve as the brains behind many AI assistants and chatbots, excelling at tasks like answering questions, summarizing text, or writing code. However, traditional LLMs remain essentially passive — they output text but cannot directly act or action (not taking about Agents). This limits their usefulness in scenarios that require tangible results, because while an LLM can tell you what to do, it won’t actually do it for you. The emerging concept of Large Action Models (LAMs) represents a transformative shift from passive language understanding to active, real-world task execution.
What are LAMs? In simple terms, a Large Action Model is an AI system that doesn’t just generate words; it generates and executes actions. A LAM can interpret a user’s request and complete the task on the user’s behalf, whether that means clicking buttons in a software application, calling an API, or even controlling a robot. In contrast to LLMs that only produce textual responses, LAMs are designed to operate within dynamic environments and carry out multi-step procedures to fulfill goals. This evolution is enabled by integrating advanced AI models with agent systems – software frameworks that connect the model to tools, memories, and real-world interfaces. The result is an AI that not only understands instructions but can also act on them, bridging the gap between understanding and execution in pursuit of real-world outcomes.
In the enterprise context – especially in sectors like Banking, Financial Services, and Insurance (BFSI) – LAMs open the door to true intelligent automation. Instead of just providing insights or recommendations, a LAM-powered system could take direct actions such as processing a transaction, verifying a document, or configuring software according to a policy. This promises significant gains in efficiency and effectiveness, marking a milestone in AI’s progression toward more general, autonomous intelligence. To understand this better, let’s compare LAMs with traditional LLMs and the interim step of multimodal models.
LLM vs. Multimodal vs. LAM: A Comparison
To put LAMs in context, it’s helpful to compare them side-by-side with standard Large Language Models and multimodal models (which extend LLMs with additional inputs/outputs like vision or audio). The table below highlights key differences in capabilities, interaction patterns, training, outputs, integration, and use cases:
| Aspect | LLMs (Large Language Models) | Multimodal Models | LAMs (Large Action Models) |
| Core Capabilities | Natural language understanding and text generation; excellent at knowledge recall, reasoning, and dialog within textual domains Primarily passive – they inform or assist with info, but do not act | Multimodal understanding – can process and relate multiple data types (e.g. text + images, audio, etc.). For example, can describe an image, answer questions about a document, or generate an image from text. Still primarily analysis/generation of content, not direct action execution. | Action-oriented intelligence – interprets user intentions and executes actions in digital or physical environments. A LAM can perform sequences of operations (clicks, API calls, robotic controls, etc.) to accomplish a goal . Goes beyond understanding to automating processes and manipulating real-world systems. |
| Interaction Style | Textual conversation or commands. Users interact via natural language prompts; the LLM responds with information or advice. No direct interface to external tools or environment (unless wrapped in an agent) | Mixed-modal interaction. Users might provide an image + a question, speak to it, or combine modalities. The model might output text explanations, classifications, or even a generated image. User engagement can be visual (e.g. pointing out parts of an image) or verbal. However, any “action” stays within giving answers or media – e.g. describing an image, not clicking a button on screen. | Agentic interaction with environments. The user can give high-level requests (e.g. “Generate a monthly report and email it to the team”), and the LAM will interact with software, devices, or other agents to make it happen. LAMs operate via an agent loop: observe environment state, decide next action, execute it, then observe again. Interaction may involve tool use (databases, APIs) and multi-turn adjustment with feedback from the environment, not just back-and-forth with the user. |
| Training Data | Trained on massive text corpora (web text, books, code, dialogues). They learn language patterns, facts, and some reasoning from text alone. Action knowledge is not explicitly learned; any ability to solve a task is through text description or code, not real executions. | Trained on combined datasets (e.g. image-caption pairs, audio transcripts, video data) in addition to text. They learn to align modalities (like matching an image to a description). Some multimodal models are pretrained separately on each modality and then merged. Training is aimed at perception and description across modalities. They typically do not learn sequences of actions or state changes, only correlations between e.g. visual input and textual output. | Trained on task demonstrations and environment interactions in addition to language. LAM development requires datasets that capture user instructions, the state of the environment (screens, system data) at each step, and the corresponding actions taken. For example, a LAM might be trained on thousands of recorded workflows (user request → step-by-step plan → executed actions). This teaches it to map from an objective (expressed in language) to a sequence of actions that achieve that objective. Training may involve limitation learning (mimicking expert trajectories) and reinforcement learning with feedback to fine-tune decision-making. |
| Inference Outputs | Textual responses. Outputs are prose, answers, code, or structured text. Even if the task is “show me a chart,” a pure LLM can only output a description or a code snippet to generate the chart. The end-result is always information, not a direct act. | Content or predictions. Depending on design, a multimodal model might output text (e.g. an explanation), a label (e.g. identifying objects in an image), or generate a new modality (e.g. create an image or speech). The output is typically consumed by a human or another system, but the model itself doesn’t act on external systems. | Action commands or tool calls. The output of a LAM at inference is an action or a series of actions. For instance, it might output something like “Click the ‘New File’ button, then type ‘Hello’ in the document” or directly produce API calls/function calls required. These actions are often represented in a structured format (like a function call, JSON, or code script) that an agent executor can immediately run. In many implementations, the LAM’s “output” effectively triggers real operations (database queries, UI clicks, robot movements, etc.). |
| Real-World Integration | Not integrated by default. LLMs live in a text-only world unless an external agent or developer connects them to other systems. For example, an LLM can propose a plan to book a flight, but a separate process must actually perform the booking. Without integration, LLMs can’t change real-world state. | Limited integration. Multimodal models expand input/output, allowing AI to perceive the world better (through images, sound, etc.), but they still don’t act on the world’s state. They might interpret a document or image that represents the real world (like a check or an ID photo) and output the info, which then a person or system uses to take action. The model itself isn’t executing changes in external systems. | Built for direct integration with environment via an agent. A LAM is typically deployed inside an agent framework that connects to real interfaces – e.g. the operating system, web browser, enterprise applications, or IoT devices. The LAM’s action outputs are grounded to actual operations: a “click” action is sent to a UI automation API, a “retrieve data” action may call a database, etc. In essence, LAMs are embedded in a loop where they continuously sense and affect the real world until the task is complete. This tight integration is what lets LAMs achieve end-to-end automation of tasks. |
| Ideal Use Cases | Language-only tasks: Chatbots for customer service, report generation, drafting emails, answering knowledge-base queries, coding assistants. LLMs shine when the output needed is information or text-based. They’re widely used for research assistance, content creation, and decision support (e.g. summarizing financial reports for an analyst) – but a human or another system will usually act on that information. | Perception and content tasks: Situations requiring understanding of both language and another modality. For example, analyzing a loan application form with both text fields and a scanned ID image (extracting text from image), or providing customer support where the user shares a screenshot of an error. Multimodal models are suited for document processing, image-based fraud detection (e.g. spotting a fake ID), medical diagnostics on image + text, etc., where interpreting mixed data is key. They can also generate rich media (e.g. create personalized visuals or audio responses). Still, a human or downstream system typically takes action based on the model’s output. | Actionable tasks and automation: This is LAMs’ home turf. They are ideal for workflow automation, robotic process automation (RPA) on steroids, and autonomous agents. In general industry: think of an AI that can operate software like a human, performing tasks such as clicking through a GUI to update records, composing and sending emails, or controlling a robot in a warehouse. In customer service, a LAM could not only draft an email response but also directly update the CRM, issue refunds, or modify an order as needed. In IT, a LAM agent might troubleshoot a system by checking logs and adjusting settings automatically. Essentially, LAMs are suited for any use case where we want to move from “assistants that suggest” to “agents that execute.” ([Large Action Models. LLMs To LAMs: The Advent Of Large… |
Architecture of Large Action Models (Technical Deep-Dive)
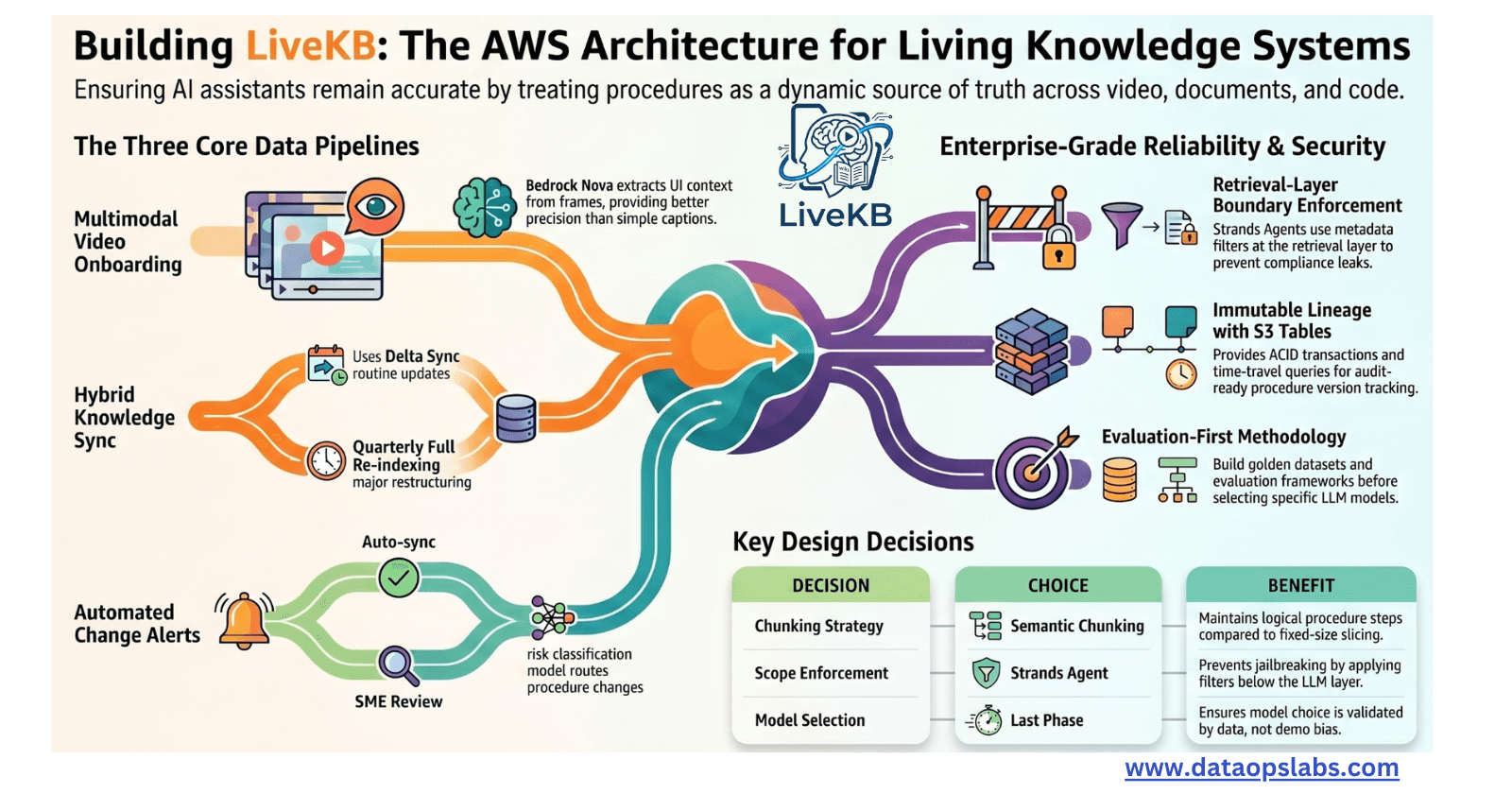
At the heart of a LAM is typically a language-model core (often an LLM) augmented with additional components that enable action-taking. A useful way to think of LAM architecture is as an agent system composed of several cooperating parts: interpretation, planning, action execution, grounding, memory, and feedback. Let’s break down these components and how they work together

Reference for the image - ([2412.10047v2.pdf]
High-level architecture of a Large Action Model integrated within an agent system.A LAM receives a user’s task request plus current environment context as input, produces a step-by-step Action Sequence*, and executes those actions through an* Action Executor*. The agent incorporates a* Memory (logging past actions and plans) and uses environment feedback (e.g. GUI state changes, API responses) to continually ground and adjust the LAM’s plan until the task is completed.
Task → Plan → Action Pipeline: When a request comes in (for example: “Open the client’s profile and generate a risk report”), the LAM first interprets the high-level goal and often generates a plan – a structured list of steps to achieve the goal. This might be implicit (happening in the model’s “thought process”) or explicit (some frameworks use a dedicated Planner module or agent). The plan is then turned into concrete actions that the system executes one by one. In advanced architectures, the LAM itself can output the next action directly, effectively interleaving planning and execution step-by-step. For instance, Microsoft’s UFO (an open-source Windows agent framework) uses the LAM as the core decision engine: the agent passes the LAM the user’s request and the current state, the LAM decides an action (like “Click ‘New’ button”), the agent executes it, then the cycle repeats for the next step. This loop continues with the LAM re-planning as needed until the goal is accomplished. By adopting such a pipeline, LAMs can handle long, multi-step tasks through iterative decision-making.
Grounding & Environment Interaction: A key challenge is making the LAM’s abstract actions actually work in a real environment. This is where grounding comes in. The agent provides the LAM with a representation of the environment – for a software GUI, this could be a list of UI elements and their properties (e.g. “Button titled ‘Submit’ at position (x,y)”). The LAM’s outputs are typically text or code describing actions (e.g. “Click the ‘Submit’ button”). The agent has an Action Executor or “control interactor” that maps these descriptions to real controls and keystrokes. In UFO’s case, it uses the Windows UI Automation API to inspect all actionable UI controls, feeding their details to the LAM, and then executes the LAM-chosen action by programmatically clicking or typing into the identified control. In a web automation scenario, the grounding might involve DOM element IDs; in a robotic scenario, it could be physical coordinates or motor commands.
The Environment continually feeds back new state data to the LAM after each action (e.g. after clicking “Submit,” the page might change – the new buttons/fields are fed back as the next state). This tight integration ensures the LAM’s actions are always tied to real, dynamic context, not just generic instructions.
Memory and Feedback Loops: LAM-based agents maintain an internal memory to handle long tasks and adaptations. The memory can store past actions, intermediate results, or any context that persists through the task. For example, if a LAM has opened a customer profile in one step, it will “remember” that state so it doesn’t repeat the step. Memory helps in conditional logic too (“if X fails, try Y next”). Every cycle, the agent supplies relevant memory back to the LAM’s input, so the model is aware of what’s been done so far. Additionally, LAMs are designed to work in a feedback loop: after each action, they can observe the outcome and adjust subsequent steps. If an unexpected situation arises (say a required form was not found or an error message appeared), an advanced LAM will dynamically re-plan to handle it.
This dynamic planning is often powered by the LAM’s ability to reason (sometimes using chain-of-thought prompting under the hood) and possibly by specialized modules. Some architectures use separate “critic” models or reward models that give feedback to the LAM on whether an action succeeded, enabling a form of self-correction or reinforcement learning during development. The end effect is that LAMs exhibit robustness and adaptability, crucial for real-world environments where things don’t always go as expected.
Planning Modules & Multi-agent Systems: Not all LAM systems rely on a single monolithic model. In some cases, a multi-agent architecture is used for efficiency and clarity. For example, one agent (or sub-model) might serve as a Planner that breaks a task into sub-tasks, and another as an Executor that carries out each sub-task. Salesforce Research’s recent work on xLAM (a family of LAMs) suggests that even relatively smaller models can be composed in an agentic way to perform complex tasks.
In a demonstration from a healthcare setting, a “Planner” LAM generated a plan for a medical assistant task and a “Caller” LAM executed API calls, together achieving high performance while remaining lightweight enough for on-device use. This modular approach can be useful in enterprise settings too – for instance, a BFSI LAM system might have one module specialized in compliance checking and another in transaction execution, coordinating their actions. Whether single-model or multi-model, the trend is to design LAMs with a clear task-plan-action pipeline where each part can be optimized and audited.
Frameworks and Examples: Two notable frameworks highlight LAM architecture in action:
Microsoft UFO (User-Facing Operations) – This project provides a blueprint for building a LAM agent on Windows OS. The UFO agent takes natural language commands (like “highlight this text in Word”), uses a LAM to plan and decide the GUI actions, and executes them on applications like Microsoft Word or Excel autonomously. UFO’s architecture (see figure above) includes components for environment state collection, a LAM inference engine, and action grounding via OS APIs, plus memory and planning modules. It demonstrates how LAMs can automate software tasks that typically required explicit programming or RPA scripts – now the model itself figures out the steps. Notably, the UFO paper outlines a full lifecycle: data collection from GUI demonstrations, a multi-phase training regimen (from learning general task plans to fine-tuning on action execution with reinforcement signals), and extensive evaluation. This provides a template that others can follow to develop LAMs for different domains.
Salesforce xLAM – Salesforce AI Research introduced xLAM, a series of Large Action Models explicitly optimized for agent tasks and tool use. The xLAM family ranges from 1B parameters up to a massive MoE (Mixture-of-Experts) model equivalent to 8×22B, and is trained on a amalgamation of high-quality agent interaction datasets. These models are designed to excel at tasks like function calling, code execution, and multi-step reasoning in tool-rich environments. In fact, the largest xLAM has demonstrated state-of-the-art tool use, even outperforming GPT-4 on a function-calling benchmark
For enterprises, xLAM points to a future where specialized action-oriented models can be plugged into AI agent frameworks (like Salesforce’s own “AgentForce” platform) to drive business process automation. Salesforce has open-sourced parts of xLAM (SalesforceAIResearch/xLAM - GitHub), signaling a growing community focus on LAM development.
Other emerging frameworks include LangChain Agents, Hugging Face Transformers Agents, and experiments like Auto-GPT – all of which explore how to chain LLMs with actions. However, LAMs take it a step further by training the model itself to be action-native. This tight coupling of language understanding with action execution is what makes LAMs so powerful for industry use. Now, let’s explore some concrete use cases, with a special focus on BFSI applications, where this technology can be a game-changer.