Adaptive Fraud Detection System Leveraging AWS Bedrock
An generative AI-based system that enables to dynamically adapt its fraud detection models to evolving fraud patterns

Introduction
Fraudulent activities pose a significant threat to businesses and individuals alike, with increasingly sophisticated methods being employed by fraudsters. Traditional fraud detection systems often struggle to keep up with evolving fraud patterns, as they rely on static models and decision-based rules that are unable to adapt to new tactics. In response to this challenge, the Adaptive Fraud Detection System emerges as an innovative solution that harnesses the power of generative artificial intelligence (AI) to dynamically enhance fraud detection capabilities.
The Adaptive Fraud Detection System is designed to continuously evolve and improve its fraud detection models by leveraging generative AI algorithms. By generating synthetic fraud data, the system ensures that it remains up-to-date with the latest fraud patterns, enabling it to detect novel and emerging fraudulent activities. This adaptive nature allows the system to overcome the limitations of traditional rule-based or static machine-learning models, which may fail to capture new fraud techniques.
The core principle behind the Adaptive Fraud Detection System lies in its ability to learn from both real and synthetic data, continuously refining its fraud detection algorithms. By iteratively training the models with synthetic data generated by generative AI algorithms, the system gains the flexibility to adapt to evolving fraud patterns. This dynamic approach empowers organizations to stay one step ahead of fraudsters, enabling timely detection and prevention of fraudulent activities. The Adaptive Fraud Detection System holds great potential to revolutionize fraud analytics by providing a proactive and adaptive defense against ever-evolving fraud threats.
Logical Architecture
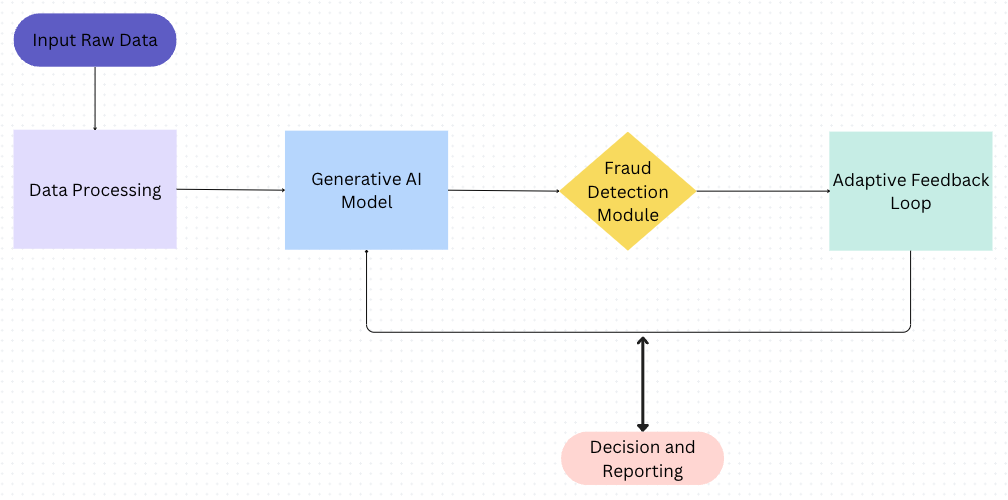
- Input Data:
- Raw transaction data: Represents the data obtained from various sources, such as credit card, debit card transaction. It includes transaction details like amount, timestamp, customer information, etc.
- Data Preprocessing:
Feature Extraction: Extract relevant features from the raw transaction data that are useful for fraud detection. This may include variables like transaction amount, location, device information, user behavior patterns, etc.
Data Transformation: Convert the extracted features into a suitable format for further processing and analysis.
- Generative AI Model:
Generative AI models use neural networks to identify the patterns and structures within existing data to generate new and original content. One of the breakthroughs with generative AI models is the ability to leverage different learning approaches, including unsupervised or semi-supervised learning for training. This has given organizations the ability to more easily and quickly leverage a large amount of unlabeled data to create foundation models or finetune the foundation model based on your dataset.
Generative AI Model is a type of artificial intelligence that is designed to create or generate new data based on existing data. It uses deep learning algorithms to analyze and understand patterns and relationships in data, and then uses that knowledge to generate new data that is similar to the original data. They are particularly useful in situations where there is a shortage of data.
- Fraud Detection Module:
Training: The fraud detection module receives a combination of real and synthetic transaction data to train a supervised or unsupervised learning algorithm. This algorithm learns to identify patterns indicative of fraudulent activity.
Testing/Inference: Once trained, the fraud detection module analyzes incoming transactions in real-time or in batches to determine their likelihood of being fraudulent. It produces a fraud score or probability for each transaction.
- Adaptive Feedback Loop:
Feedback Collection: The fraud detection module collects feedback on the accuracy of its predictions, such as through manual reviews, reported fraud cases, or historical data.
Model Update: The feedback is used to update and improve the generative AI model and the fraud detection algorithm. This ensures that the system adapts to new types of fraud and improves its detection capabilities over time.
- Decision and Reporting:
Decision Logic: Based on the fraud scores or probabilities generated by the fraud detection module, a decision logic component determines whether a transaction should be flagged as potentially fraudulent or allowed to proceed.
Reporting: Relevant stakeholders, such as fraud analysts or system administrators, receive reports and notifications regarding detected fraud instances, suspicious activities, and system performance.
Input Data and Preprocessing
Dataset for Fraudulent activities varies based on different use cases and scenarios e.g)

In a Financial Organization these data could have been stored in different systems and we need to identify the fraudulent data points and preprocess the data which are important for fraud detection.
Here I am taking an example of Fraudulent Transaction with the below features in the dataset.

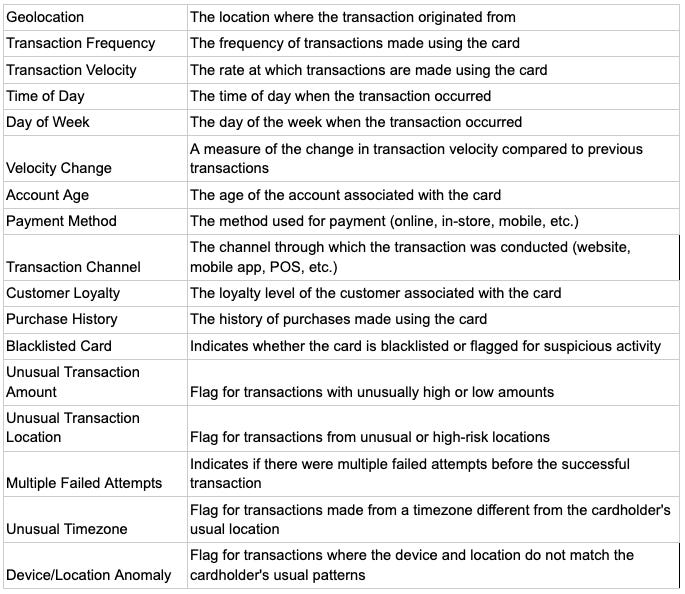
Example Data (Synthesized)
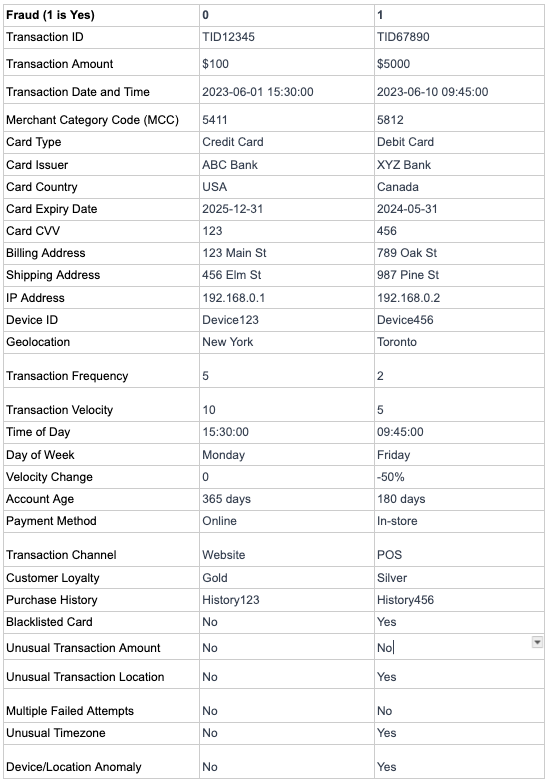
Less Important Features
Post Data Processing and the EDA identified below features are less relevant to the prediction of fraud transactions.

Leveraging Generative AI
Generative AI can create synthetic data for fraud transaction detection. Generative AI models can be trained on legitimate transaction data to generate synthetic data that resembles fraudulent transaction data. This synthetic data can be used to augment the training dataset for machine learning models used for fraud detection.
By using synthetic data, the machine learning models can be trained on a larger and more diverse dataset, which can improve their accuracy and performance in detecting fraudulent transactions. It can also help to address the issue of imbalanced datasets, where there are significantly fewer instances of fraudulent transactions than legitimate transactions.
However, it is important to note that the use of synthetic data for fraud transaction detection should be done with caution. The synthetic data should be generated based on a thorough understanding of the characteristics of fraudulent transactions, and the machine learning models should be rigorously validated to ensure that they are effective in detecting real-world fraudulent transactions.
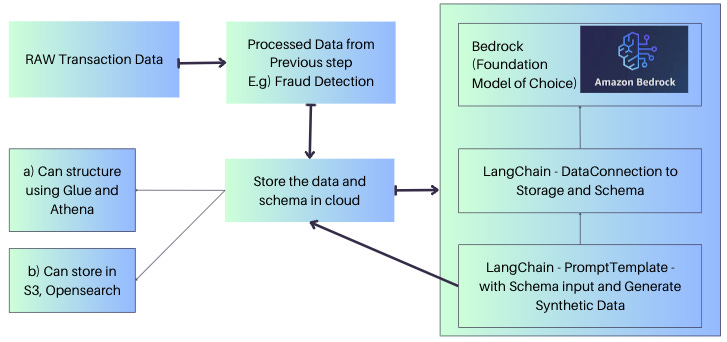
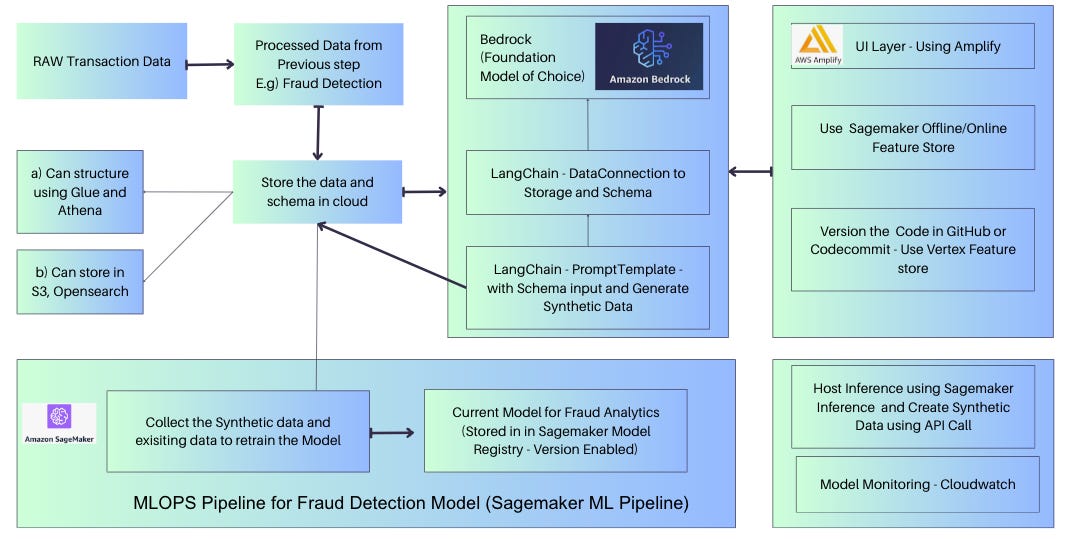
Adaptive Fraud Detection System Architecture with Feedback
The Adaptive Fraud Detection System employs a sophisticated architecture designed to detect and prevent fraudulent activities in an adaptive and dynamic manner. At its core, the system comprises three main components: data processing, generative AI algorithms, and adaptive learning. The data processing pipeline serves as the initial stage, where raw data from various sources, such as financial transactions, user behavior logs, and external data feeds, are collected and preprocessed. This preprocessing step involves data cleansing, feature engineering, and normalization to ensure the data is in a suitable format for analysis.
The generative AI algorithms play a crucial role in the Adaptive Fraud Detection System. These algorithms leverage AWS Bedrock and choose the foundation Model of Choice (e.g Claude, LLAMA2, Titan to generate synthetic fraud data. By training the generative models on a combination of genuine and historical fraudulent data, the system can generate realistic synthetic fraud instances. This synthetic data serves as a valuable resource for training and fine-tuning the fraud detection models. The generative AI algorithms capture the underlying patterns and characteristics of fraud, enabling the system to learn and adapt to evolving fraud techniques.
The generated synthetic fraud data is integrated into the data processing pipeline, where it is combined with the real-world data. This merged dataset is used to train and update the fraud detection models. The adaptive learning mechanism employed by the Adaptive Fraud Detection System allows it to continuously improve its fraud detection models over time. As new data becomes available and fraud patterns evolve, the system leverages this data to refine its models, enhancing their accuracy and adaptability. The adaptive learning process involves iterative model training, where the system analyzes the performance of the current models, identifies areas of improvement, and incorporates new data to update the models accordingly.
To ensure the adaptability of the fraud detection models, the Adaptive Fraud Detection System employs techniques such as transfer learning and online learning. Transfer learning enables the system to leverage knowledge learned from similar fraud patterns and apply it to new and unseen fraud instances. This helps to improve the system's ability to detect emerging fraud tactics. Online learning, on the other hand, allows the system to update its models in real-time as new data streams in. This real-time adaptation ensures that the fraud detection system remains up-to-date and effective in identifying and preventing fraud.
Overall, the Adaptive Fraud Detection System architecture integrates data processing, generative AI algorithms, and adaptive learning mechanisms to create a robust and flexible fraud detection solution. By incorporating synthetic fraud data generated through generative AI, the system expands its training data and enhances its ability to detect evolving fraud patterns. Through adaptive learning and continuous model updates, the system adapts to changing fraud tactics, ensuring accurate and proactive fraud detection. The architecture of the Adaptive Fraud Detection System positions it as an innovative and effective tool for organizations seeking to combat fraud in a dynamic and adaptive manner.
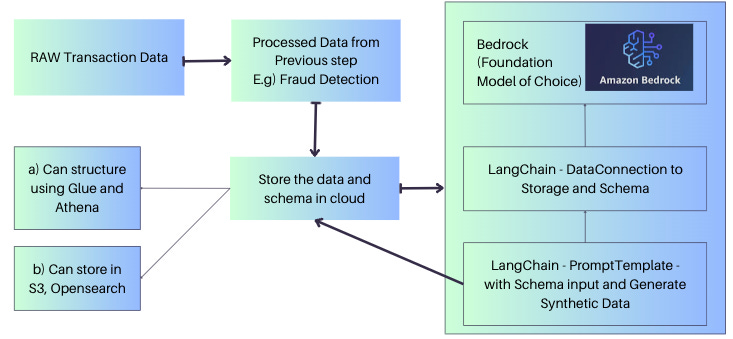
Dynamic Model Adaptation
Dynamic model adaptation is a key feature of the Adaptive Fraud Detection System, enabling it to effectively respond to emerging fraud patterns. The system leverages generative AI techniques to adapt its fraud detection models. As new fraud patterns emerge, the generative AI algorithms in the system analyze the characteristics of these patterns and generate synthetic fraud data that represents these new instances. This synthetic data is then incorporated into the training process, allowing the system to learn and adapt to the evolving nature of fraud.
The adaptive fraud detection system employs an iterative training process that continually refines and updates its fraud detection models. The system incorporates real-time data, including both genuine and potentially fraudulent transactions, to continuously train the models and improve their accuracy. By incorporating real-time data, the system can capture and adapt to the changing dynamics of fraud in real-world scenarios. The iterative nature of the training process allows the system to continuously learn from new data, refine its fraud detection algorithms, and enhance its capability to identify and prevent fraudulent activities. This dynamic model adaptation ensures that the Adaptive Fraud Detection System remains effective in keeping up with the ever-evolving landscape of fraud.
Performance Evaluation and Case Studies
The performance evaluation of the Adaptive Fraud Detection System provides insights into its effectiveness in detecting and preventing fraudulent activities. Various metrics are utilized to assess its performance, including precision, recall, and false-positive rates. Precision measures the proportion of correctly identified fraud cases out of all the cases flagged as fraudulent, highlighting the system's accuracy. Recall, on the other hand, measures the proportion of actual fraud cases that were correctly identified by the system, indicating its ability to capture fraudulent activities. The false-positive rate quantifies the rate at which legitimate transactions are incorrectly flagged as fraudulent. Through comprehensive performance evaluation, the Adaptive Fraud Detection System can gauge its strengths and areas for improvement, enhancing its overall fraud detection capabilities.
In addition to performance evaluation, real-world case studies demonstrate the Adaptive Fraud Detection System's practical effectiveness in detecting and preventing fraud incidents. These case studies showcase specific instances where the system successfully identified and prevented fraudulent activities, protecting organizations from financial losses and reputational damage. The case studies highlight the adaptability and accuracy of the system in dealing with various types of fraud, such as credit card fraud, identity theft, and insider fraud. By presenting these real-world scenarios, the case studies provide concrete evidence of the system's value in mitigating fraud risks and showcasing its potential to be implemented across diverse industries.
The results of performance evaluations, along with the real-world case studies, offer a comprehensive understanding of the Adaptive Fraud Detection System's capabilities and its impact on fraud prevention. The performance metrics provide quantitative measures of the system's accuracy and effectiveness, while the case studies provide qualitative evidence of its practical success. Together, these insights support the adoption and implementation of the Adaptive Fraud Detection System as a reliable and efficient solution for organizations seeking to combat fraud. By highlighting both the system's technical performance and its real-world application, stakeholders can gain confidence in its ability to protect against fraudulent activities and make informed decisions regarding its integration into their fraud prevention strategies.
Future Developments and Challenges
The future of the adaptive fraud detection system holds promising advancements and developments. One potential direction is the integration of advanced machine learning techniques, such as deep reinforcement learning, to enhance the system's ability to learn and adapt in dynamic fraud environments. This could enable the system to autonomously optimize its fraud detection models and decision-making processes. Additionally, advancements in natural language processing (NLP) and sentiment analysis could be leveraged to analyze textual data, such as customer reviews and social media posts, to identify potential fraud indicators and enhance fraud detection accuracy. Furthermore, the integration of advanced anomaly detection algorithms, anomaly explanation techniques, and visualization tools could provide deeper insights into the system's decision-making processes, improving transparency and interpretability.
Despite the potential future developments, the adaptive fraud detection system faces several challenges. One significant challenge is ensuring data privacy and compliance with regulations, especially when dealing with sensitive customer information. Striking a balance between effective fraud detection and preserving data privacy will be crucial. Model interpretability is another challenge, as the complexity of generative AI algorithms can make it difficult to understand and explain the system's decision-making processes. Overcoming this challenge will be essential to gain stakeholders' trust and ensure regulatory compliance. Additionally, scalability poses a challenge, as the system needs to handle large volumes of real-time data from various sources. Developing efficient data processing and storage mechanisms will be critical to ensure the system's scalability without compromising performance.
Addressing these challenges requires collaboration between industry experts, researchers, and policymakers. It is crucial to establish robust frameworks and guidelines that promote responsible and ethical use of the adaptive fraud detection system. Striving for transparency and interpretability in the system's algorithms and decision-making processes will help build trust among stakeholders and enable effective auditing. Furthermore, ongoing research and development efforts should focus on techniques that can handle large-scale, heterogeneous data while maintaining data privacy and security. By addressing these challenges and capitalizing on future advancements, the adaptive fraud detection system can continue to evolve, providing organizations with robust fraud prevention solutions that adapt to the ever-changing landscape of fraudulent activities
Conclusion
In conclusion, the adaptive fraud detection system represents a significant advancement in combating evolving fraud patterns. By leveraging generative AI techniques, the system can adapt to emerging fraud techniques and continuously improve its accuracy in detecting and preventing fraudulent activities. The system's ability to generate synthetic fraud data enhances the training process and expands the system's understanding of fraud patterns. The integration of adaptive learning mechanisms, real-time data processing, and iterative model updates further strengthens its effectiveness in proactively identifying and mitigating fraud risks. The adaptive fraud detection system offers organizations a robust and dynamic solution to stay ahead of fraudsters and protect their assets, customers, and reputation.
The potential of generative AI for dynamic fraud prevention is immense and has significant implications for future fraud analytics. The ability to generate synthetic fraud data enables organizations to overcome the limitations of limited real-world fraud data and enhance their fraud detection models' performance. As generative AI techniques continue to advance, the system can simulate rare and anomalous fraud scenarios, improving its ability to identify sophisticated fraud techniques. Furthermore, the adaptive nature of the system, coupled with the integration of advanced machine learning and data processing techniques, holds promise for the future of fraud prevention. By embracing generative AI and incorporating it into fraud analytics, organizations can develop more effective and adaptable strategies to combat ever-evolving fraud patterns and safeguard their operations.